

Beyond Wins and Losses: How to Learn from Inconclusive A/B Tests
A practical framework for extracting learning when experiments don’t reach statistical significance.


A/B testing is often framed as a search for clear wins. In practice, however, many experiments do not produce statistically significant results.
👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams.
These inconclusive outcomes are not failures but rather a natural part of experimentation and, when handled correctly, can generate valuable insight.
This post explores how to think about inconclusive A/B tests, how to extract learning from them, and how leading companies treat experimentation as a learning system rather than a win–loss scoreboard.
The Spectrum of Experiment Outcomes
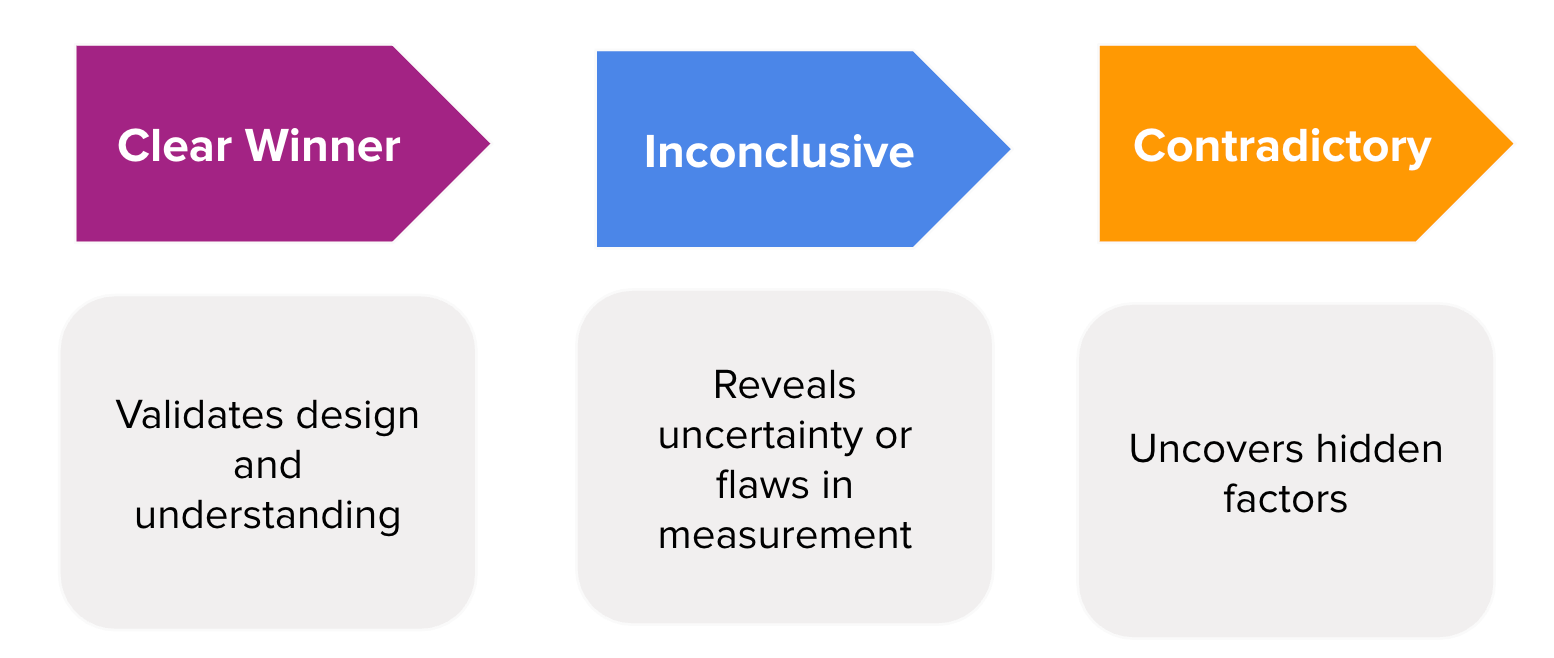
Experiment outcomes exist on a spectrum rather than as binary wins or losses. Each point on this spectrum reflects a different balance of signal, noise, and understanding.
A clear winner occurs when results are both statistically and practically significant, leading to confident decisions.
Inconclusive results occur when confidence intervals overlap zero. While these results lack a definitive directional outcome, they frequently expose uncertainty, validate assumptions, or highlight flaws in measurement or design.
Contradictory results arise when different metrics or segments tell different stories, often revealing deeper product dynamics or trade-offs.
Industry analyses across large experimentation programs show that clear wins are relatively rare. A large-scale analysis of more than 28,000 A/B tests found that only about 14-20% of experiments reach the 95% confidence threshold, meaning that most tests do not deliver a clean uplift and instead fall into neutral, contradictory, or inconclusive outcomes.
Source: https://www.gomage.com/blog/why-most-a-b-tests-fail-and-how-to-turn-every-result-into-a-win/
What Is an Inconclusive Test?
Let’s take a deeper look at inconclusive tests. An experiment is considered statistically inconclusive when its results do not reach statistical significance, meaning the confidence interval includes zero. This often occurs even when the observed effect may be practically meaningful, highlighting a misalignment between statistical significance and practical significance, as illustrated in the graph below.
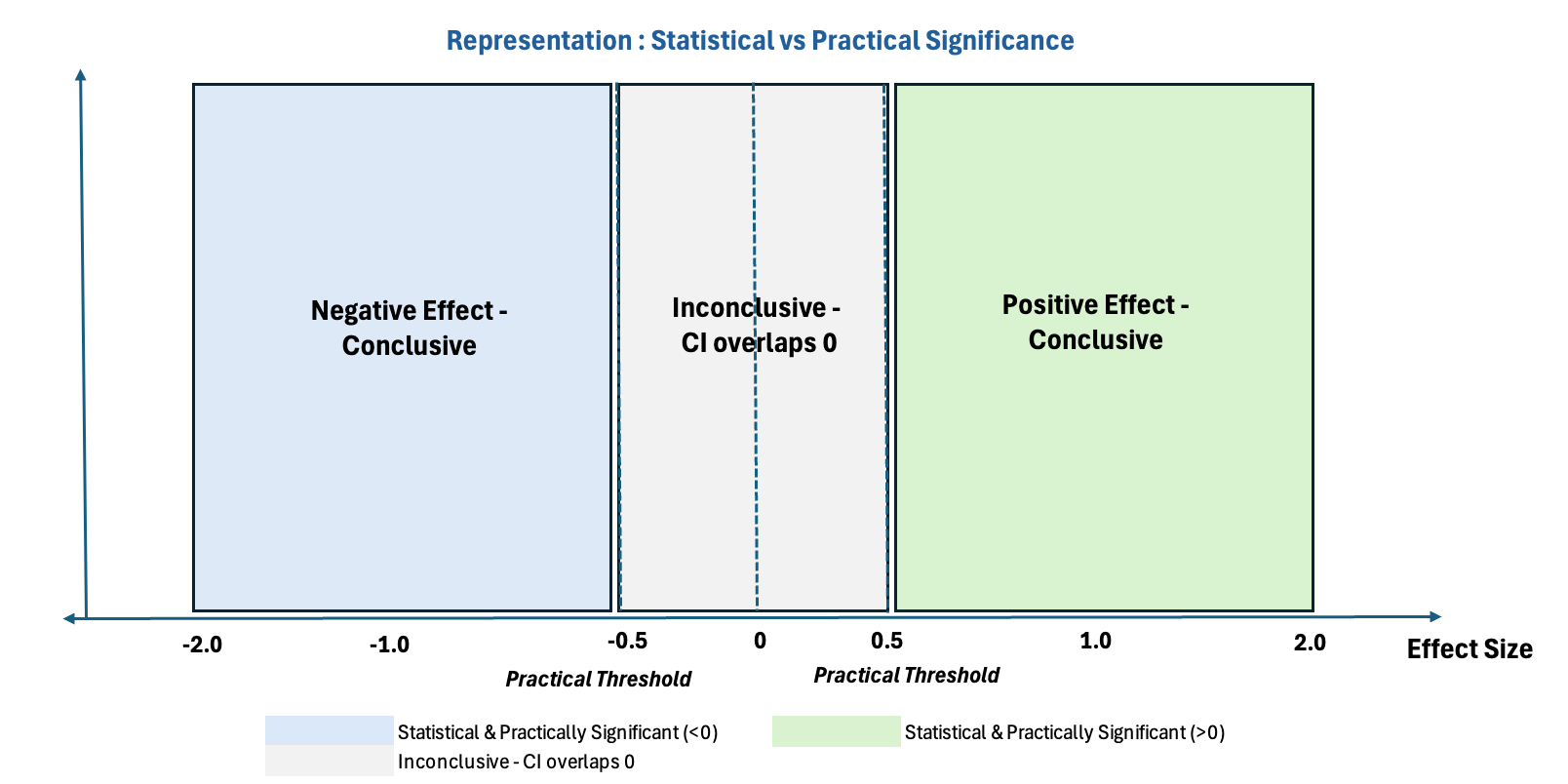
Statistically inconclusive tests commonly occur because:
The true effect size is small, making it difficult to detect a meaningful lift without very large samples, even if the change is directionally correct.
The experiment is underpowered, either due to insufficient traffic, short test duration, or optimistic assumptions about the expected impact.
Variance is higher than expected, often driven by heterogeneous user behavior, seasonality, or noisy metrics that widen confidence intervals.
The metric does not fully capture the intended behavior, especially when it is too far downstream or weakly aligned with the product change.
Turning Inconclusive Tests into Insight
Inconclusive results become valuable when approached through a structured diagnostic framework.
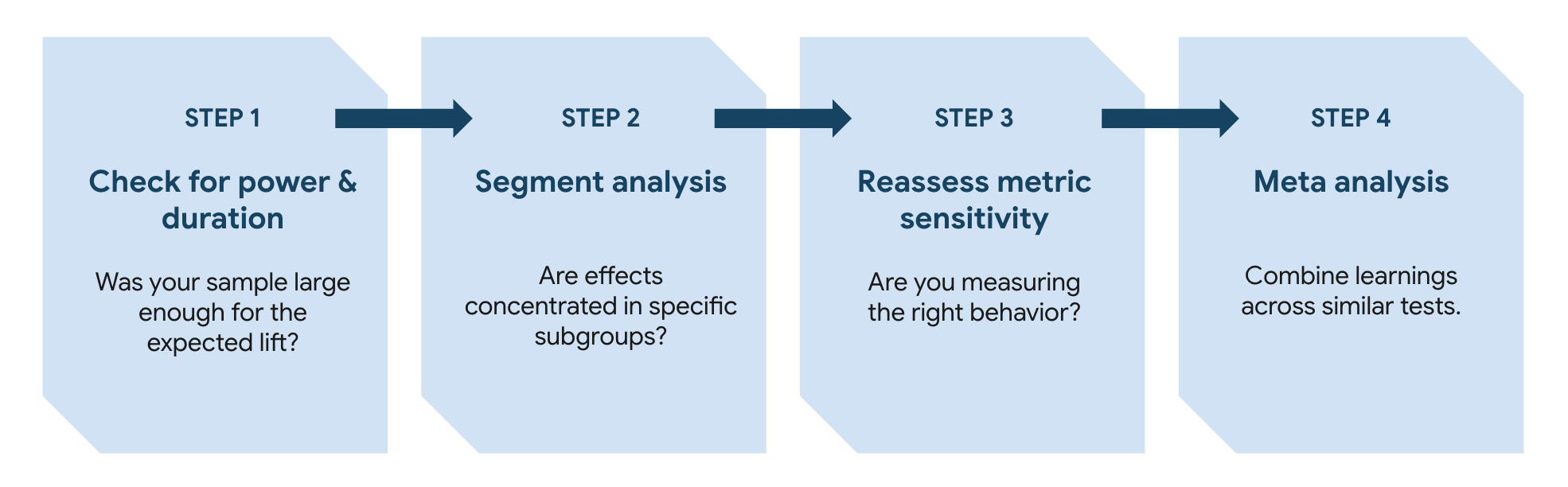
Step 1: Check Power and Duration
The first question is whether the experiment was sufficiently powered for the expected effect size. Many inconclusive tests simply lack enough data to detect meaningful change, even when a real effect exists.
Example:
A checkout UI change is expected to improve conversion by 0.3%, but the experiment is powered to detect only 1% lifts. After two weeks, the result is inconclusive, not because the change had no impact, but because the test was never capable of detecting such a small improvement.
This step helps distinguish between no effect and insufficient evidence.
Shameless Plugs:
A/B Testing Course for Data Scientists and Product Managers
Learn how top product data scientists frame sharp hypotheses, choose the right metrics, and turn A/B results into clear product decisions.
Advanced A/B Testing for Data Scientists
Master the experimentation frameworks used by leading tech teams to design rigorous tests and analyze results with confidence.
Build a strong problem-solving mindset and leverage data-driven strategies—A/B testing, ML, and causal inference—to influence real product outcomes.
Step 2: Segment Analysis
Even when the overall effect is neutral, meaningful signals often appear within specific user segments, such as new versus repeat users, power users, geographies, or usage contexts.
Example:
An ETA algorithm shows no overall lift in orders, but new users convert less while repeat users convert more. The aggregate result looks neutral, but segment analysis reveals a clear trade-off that informs rollout decisions.
Segment-level analysis uncovers heterogeneous effects that averages conceal.
Step 3: Reassess Metric Sensitivity
An inconclusive result may indicate that the chosen metric is too noisy, too far downstream, or poorly aligned with the product change.
Example:
A recommendation ranking change is evaluated using long-term retention, which barely moves in a two-week test. When the team instead looks at session depth or content saves, a clearer signal emerges that explains future retention trends.
Re-evaluating metric choice often leads to clearer insights in follow-up experiments.
Step 4: Meta-Analysis Across Experiments
No experiment exists in isolation. Aggregating results across similar tests can reveal consistent patterns that individual experiments cannot detect on their own.
Example:
A single onboarding experiment shows no significant lift, but when combined with results from five similar onboarding tests, a consistent small positive trend appears, strong enough to justify a design direction.
Meta-analysis shifts the focus from single-test outcomes to cumulative learning.
Beyond Winning: Spotify’s Experiments with Learning Framework
As experimentation programs scale, even industry leaders like Spotify are reframing what success means, moving beyond a simple win–loss mindset.
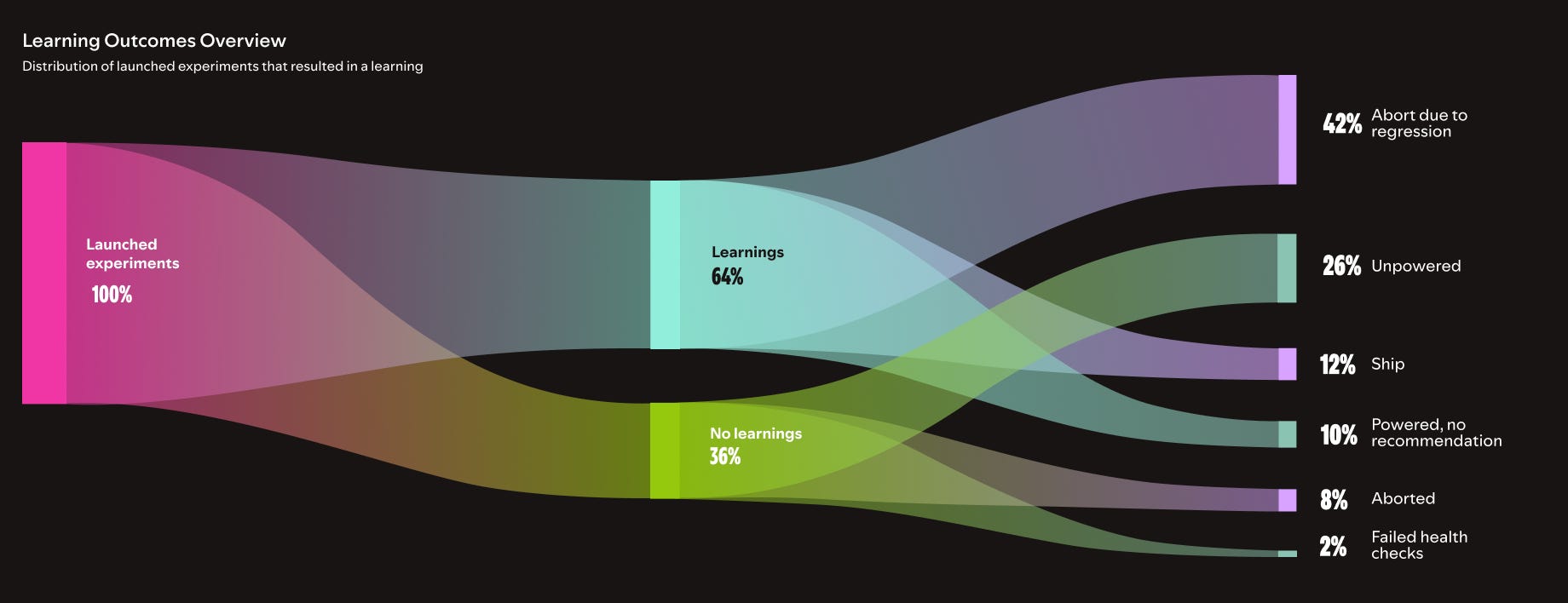
Spotify runs thousands of experiments each year across product, design, and infrastructure. When evaluated purely on lift, many of these experiments appear neutral or inconclusive. Rather than viewing this as a limitation, Spotify recognized that focusing only on win rate undervalues the true purpose of experimentation.
To address this, Spotify introduced the Experiments with Learning (EwL) framework:
https://engineering.atspotify.com/2025/9/spotifys-experiments-with-learning-framework
Under EwL:
Success is measured by the Learning Rate - the percentage of valid experiments that produce actionable insights instead of win rate.
Neutral or inconclusive results are considered valuable if they clarify user behavior, invalidate assumptions, or inform future design decisions.
An internal confidence platform automates checks, documentation, and learning capture, reinforcing a learning-first experimentation culture.
As Spotify summarizes this philosophy:
“A failed test can still be a successful experiment if it produces a learning.”
— Spotify Engineering Blog, 2025
Closing Thoughts
Inconclusive A/B tests are not a problem to eliminate, they are a signal to investigate more deeply. By applying structured diagnostics and valuing learning over lift, teams can turn uncertainty into progress.
If you’d like to dive deeper into experimentation, here are a few of our learning programs you might enjoy:
A/B Testing Course for Data Scientists and Product Managers
Learn how top product data scientists frame hypotheses, pick the right metrics, and turn A/B test results into product decisions. This course combines product thinking, experimentation design, and storytelling—skills that set apart analysts who influence roadmaps.
Advanced A/B Testing for Data Scientists
Master the experimentation frameworks used by leading tech teams. Learn to design powerful tests, analyze results with statistical rigor, and translate insights into product growth. A hands-on program for data scientists ready to influence strategy through experimentation.
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML, and Causal Inference, to drive product growth.
Not sure which course aligns with your goals? Send me a message on LinkedIn with your background and aspirations, and I’ll help you find the best fit for your journey.
 | A guest post by
|