

Building a RAG Q&A Chatbot Using LangChain
Build a RAG chatbot that answers questions about the cutting-edge “Attention is All You Need” research paper.


👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams.
Introduction
Large Language Models (LLMs) have demonstrated impressive language generation capabilities. However, their knowledge is limited to their training data, making them prone to hallucinations when answering domain-specific queries. Retrieval-Augmented Generation (RAG) addresses this limitation by supplementing LLMs with an external knowledge base, ensuring responses are grounded in relevant, retrieved documents.
In this blog, we build a RAG-based chatbot using LangChain that can answer questions about Attention Is All You Need, the seminal paper introducing Transformers. We will cover document loading, chunking, embedding generation, and retrieval, forming the foundation for our chatbot
About the Authors:
Arun Subramanian: Arun is an Associate Principal of Analytics & Insights at Amazon Ads, where he leads development and deployment of innovative insights to optimize advertising performance at scale. He has over 12 years of experience and is skilled in crafting strategic analytics roadmap, nurturing talent, collaborating with cross-functional teams, and communicating complex insights to diverse stakeholders.
Manisha Arora: Manisha is a Data Science Lead at Google Ads, where she leads the Measurement & Incrementality vertical across Search, YouTube, and Shopping. She has 11+ years experience in enabling data-driven decision making for product growth.
Introduction
In our previous article, we learnt about the LangChain framework, different components and built a simple LLM powered Streamlit UI to interact with. In this article, we will take it a notch higher by adding a little bit more complexity. First, we will explore how to build a Retrieval Augmented Generation (RAG)Q&A chatbot using LangChain components. Second, we are going to separate out the presentation tier (Streamlit) that the user interacts with and the application tier (FastAPI) where our code logic resides.
Why Retrieval Augmented Generation (RAG)?
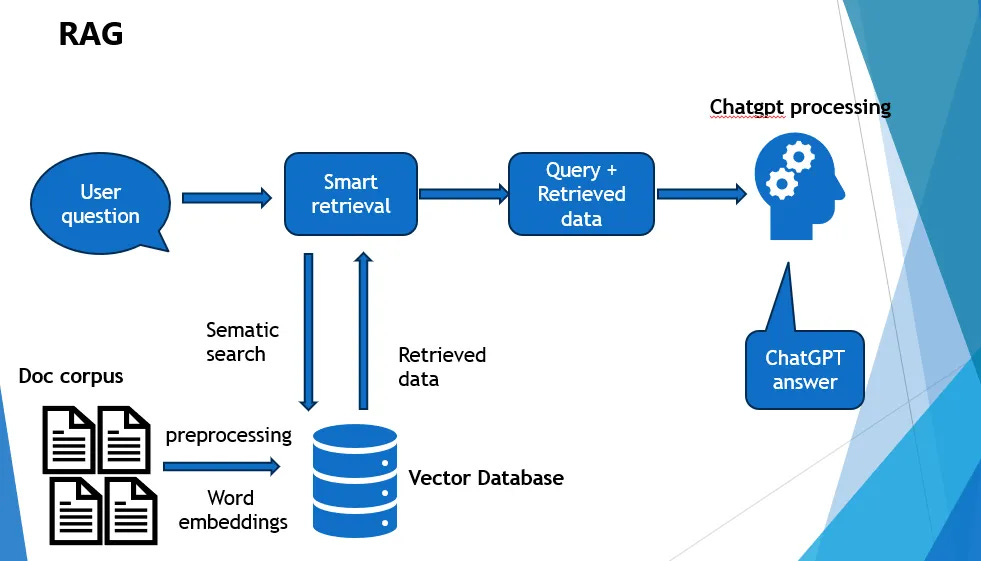
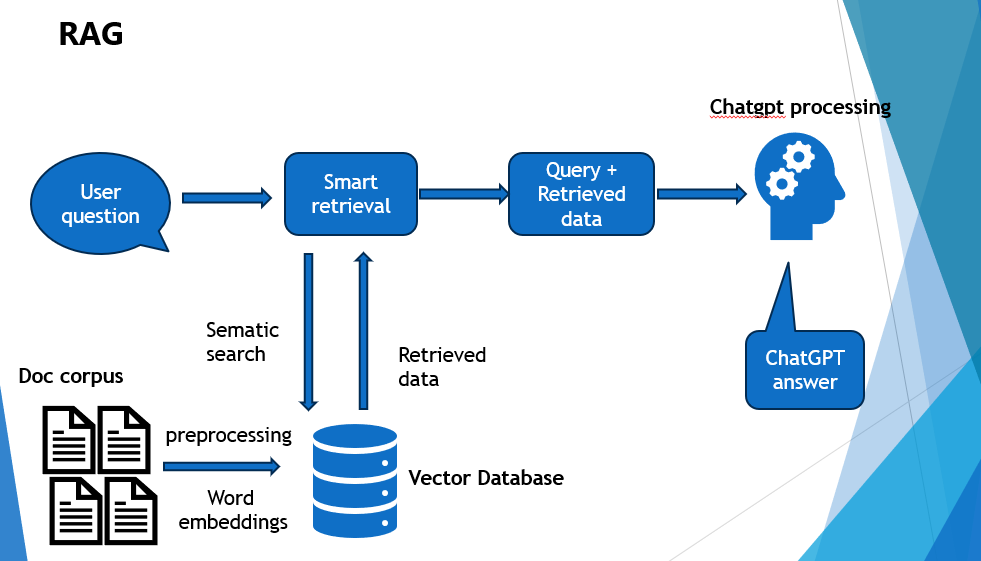
Reference Image - https://miro.medium.com/v2/resize:fit:981/1*FdDtFV3XmzCw0aU93yYrvA.png
{kind=link}
Retrieval Augmented Generation (RAG) is a technique used to enhance the accuracy and reliability of Large Language Models (LLMs) by grounding them in external knowledge sources. It involves retrieving relevant information from a corpus of documents and providing it to the LLM as context for generating a response. So they enhance LLMs by integrating information retrieval with text generation. Instead of relying solely on pre-trained knowledge, a RAG pipeline retrieves relevant documents based on user queries, passing them as context to the LLM. This approach improves factual accuracy, ensures up-to-date information, and reduces hallucinations.
Key components of RAG:
Retriever: Fetches relevant documents from a knowledge base.
LLM: Generates responses using retrieved documents as context.
Augmentation: The retrieved documents supplement LLM inputs to refine responses.
For our chatbot, we will process the Attention Is All You Need paper and enable retrieval-based Q&A.
Loading the documents
LangChain provides different DocumentLoaders that can help load data into the standard LangChain Document format. Sources can include text files, PDFs, CSVs, web pages, databases,etc. Each DocumentLoader has its own specific parameters, but they can all be invoked in the same way with the .load method. An example use case is as follows:

This extracts the text while preserving its structure.
Chunking
Once you've loaded documents, you'll often want to transform them to better suit your application. This process offers several benefits, such as ensuring consistent processing of varying document lengths, overcoming input size limitations of models, and improving the quality of text representations used in retrieval systems.
At a high level, text splitters work as following:
Split the text up into small chunks using the appropriate approach. Available approaches are a) length based, b) text-structure based, c) document-structure based or d) semantic meaning based
Start combining these small chunks into a larger chunk until you reach a certain size (as measured by some function).
Once you reach that size, make that chunk its own piece of text and then start creating a new chunk of text with some overlap (to keep context between chunks).
LangChain offers many different types of text splitters. An example of `Recursive` splitter is as follows:

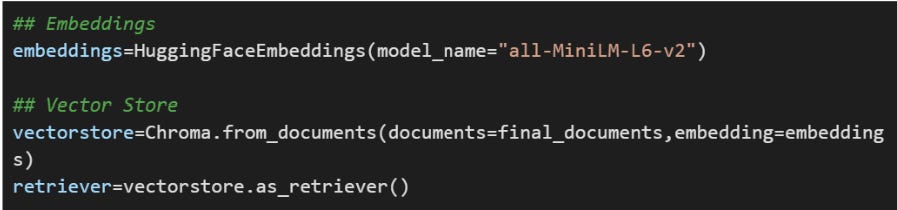
Creating Embeddings, storing in Vector Store and using it as a Retriever
Imagine being able to capture the essence of any text - a tweet, document, or book - in a single, compact representation. This is the power of embedding models, which lie at the heart of many retrieval systems. Embedding models transform human language into a format that machines can understand and compare with speed and accuracy. These models take text as input and produce a fixed-length array of numbers, a numerical fingerprint of the text's semantic meaning. Embeddings allow search systems to find relevant documents not just based on keyword matches, but on semantic understanding.
Vector stores are specialized data stores that enable indexing and retrieving information based on vector representations. Vector stores are frequently used to search over unstructured data, such as text, images, and audio, to retrieve relevant information based on semantic similarity rather than exact keyword matches. Once you construct a vector store, it’s very easy to construct a retriever.
LangChain provides a universal interface for working with different Embedding models and Vector stores. Here is example usage:
Building a RAG chain
This is where we bring Retriever, LLM and Prompt together. First, the user's query is converted into an Embedding and passed on to the retriever to search for semantically similar text or documents. Then the retrieved documents are stuffed into the Prompt as context along with the user’s original query and passed on to the LLM model to generate an answer. Let's walk through an example.

Conclusion
We have successfully built a RAG-based chatbot that retrieves and processes external knowledge to improve response accuracy. This serves as the foundation for the next step: deploying the chatbot using a two-tier architecture with FastAPI and Streamlit.
Stay tuned for the next blog, where we will deploy this system into a scalable, interactive web application!
References:
https://python.langchain.com/v0.1/docs/get_started/introduction
Check out my upcoming courses:
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML, and Causal Inference, to drive product growth.
AI/ML Projects for Data Professionals
Gain hands-on experience and build a portfolio of industry AI/ML projects. Scope ML Projects, get stakeholder buy-in, and execute the workflow from data exploration to model deployment. You will learn to use coding best practices to solve end-to-end AI/ML Projects to showcase to the employer or clients.
Not sure which course aligns with your goals? Send me a message on LinkedIn with your background and aspirations, and I'll help you find the best fit for your journey.
 | A guest post by
|