

Building Scalable ML Architectures: Best Practices and Patterns
Explore the comprehensive guide that discusses key strategies and design patterns for developing robust, scalable machine learning systems.


👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams.
In the rapidly evolving field of machine learning (ML), the ability to build scalable architectures is crucial. Scalability ensures that your ML systems can handle increasing amounts of data, users, and requests without compromising performance. In this post, we'll explore best practices and patterns for building scalable ML architectures, drawing from industry experiences and insights.
Understanding Scalability in ML
Scalability in ML involves designing systems that can grow efficiently as demand increases. This includes handling larger datasets, more complex models, and higher request volumes. A scalable ML architecture ensures that your models can be trained, deployed, and maintained effectively, regardless of scale.
1. Decoupling Components
One of the fundamental principles of building scalable ML architectures is decoupling different components of the system. This involves separating data ingestion, preprocessing, model training, and deployment into distinct, independently scalable services.

Image Credits: https://www.linkedin.com/pulse/machine-learning-project-life-cycle-kishore-babu
Best Practices:
Use message queues (e.g., Kafka, RabbitMQ) for communication between services.
Implement microservices architecture to ensure each component can scale independently.
Employ containerization (e.g., Docker) to manage and deploy services efficiently.
2. Leveraging Distributed Computing
For large-scale ML tasks, leveraging distributed computing frameworks is essential. Distributed computing allows you to parallelize data processing and model training across multiple nodes, significantly reducing time and resource consumption.

Best Practices:
Use frameworks like Apache Spark, Dask, or Ray for distributed data processing.
Implement distributed training with libraries like TensorFlow's tf.distribute or PyTorch's torch.distributed.
Optimize resource allocation using cluster managers like Kubernetes or Apache Mesos.
3. Efficient Data Management
Scalable ML architectures require efficient data management practices to handle vast amounts of data seamlessly. This involves optimizing data storage, retrieval, and processing pipelines.
Best Practices:
Use scalable data storage solutions like Amazon S3, Google Cloud Storage, or HDFS.
Implement data versioning and lineage tracking with tools like DVC (Data Version Control) or MLflow.
Optimize data pipelines with ETL (Extract, Transform, Load) tools like Apache Airflow or Prefect.
Shameless plugs:
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML, and Causal Inference, to drive product growth.
AI/ML Projects for Data Professionals
Gain hands-on experience and build a portfolio of industry AI/ML projects. Scope ML Projects, get stakeholder buy-in, and execute the workflow from data exploration to model deployment. You will learn to use coding best practices to solve end-to-end AI and ML Projects to showcase to the employer or clients.
4. Model Training and Optimization
Scalable model training involves using techniques and tools that can handle large datasets and complex models without compromising on performance or accuracy.
Best Practices:
Use data parallelism and model parallelism strategies for training large models.
Implement hyperparameter tuning at scale with frameworks like Optuna or Hyperopt.
Utilize pre-trained models and transfer learning to reduce training time and computational resources.
Understanding data parallelism and model parallelism:
Model parallelism involves splitting the model itself across multiple machines, and training different parts of the model on different machines. This approach is useful when the model is too large to fit in the memory of a single machine, or when certain parts of the model require more computation than others. Model parallelism is a bit more complex to implement and is less common than data parallelism, but is still used in some specialized applications.
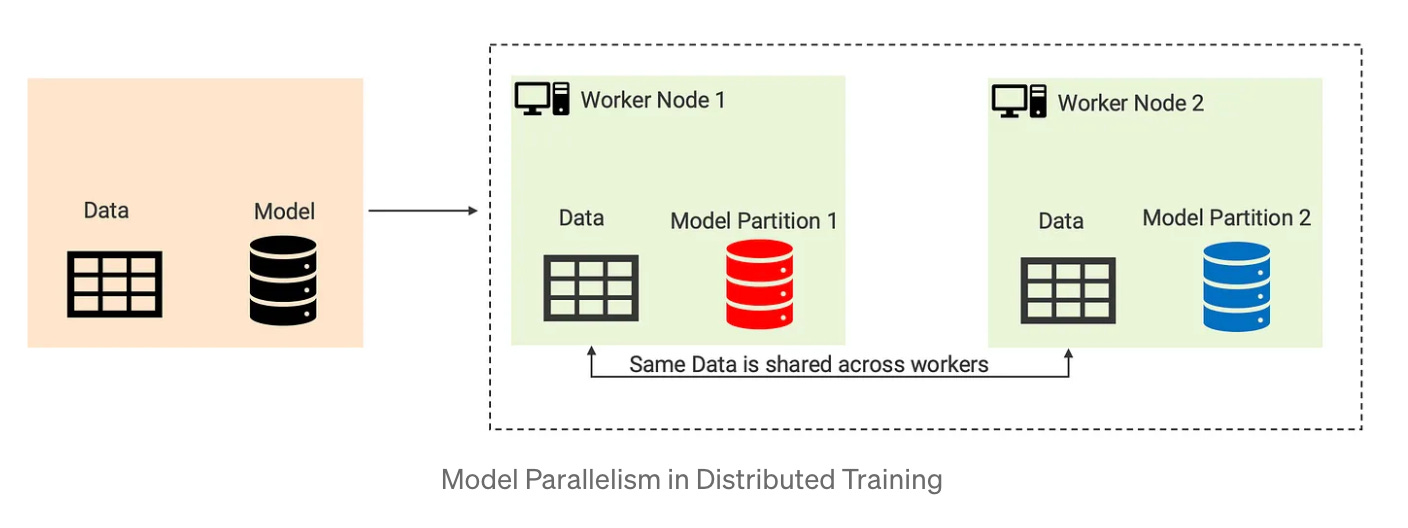
Image Credits: https://medium.com/@rachittayal7/a-gentle-introduction-to-distributed-training-of-ml-models-81295a7057de
Data parallelism involves splitting the training data across multiple machines and training a copy of the model on each machine using its own portion of the data. The models are then synchronized periodically to ensure that they all have the same weights. This approach works well when the models are large and the training data is plentiful, as it allows for efficient use of computing resources. In this article, we are going to focus on data parallelism in depth and see an example code of how we can perform that using Pytorch.
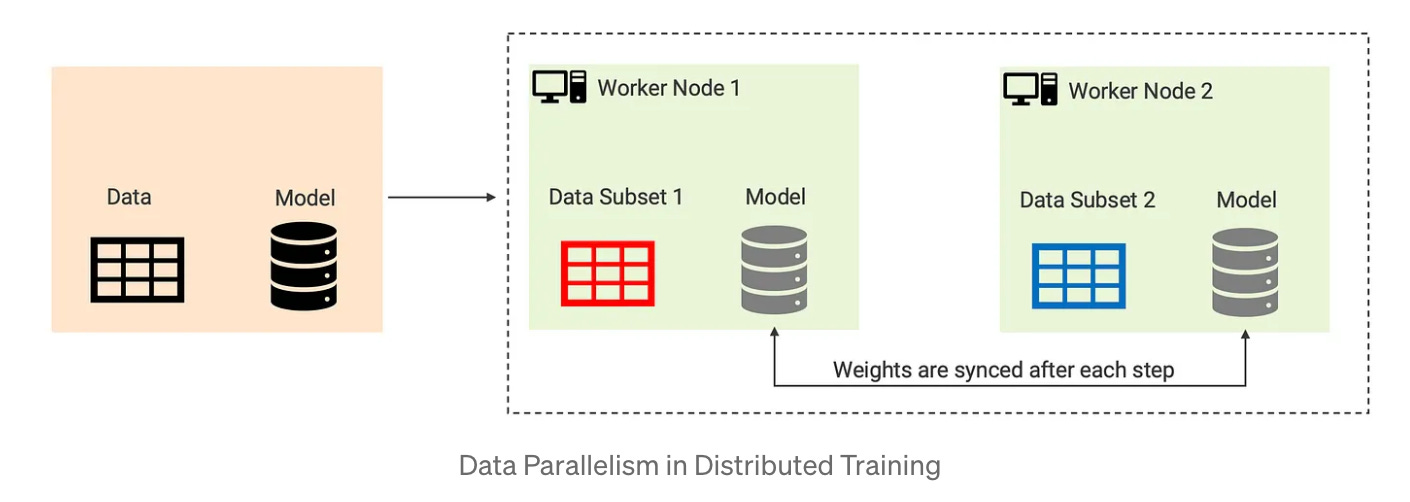
Image Credits: https://medium.com/@rachittayal7/a-gentle-introduction-to-distributed-training-of-ml-models-81295a7057de
5. Model Deployment and Monitoring
Deploying and monitoring models at scale requires robust practices to ensure models perform well in production and adapt to changing data distributions.
Best Practices:
Use model serving platforms like TensorFlow Serving, TorchServe, or ONNX Runtime for efficient deployment.
Implement A/B testing and canary releases to gradually roll out new models.
Monitor model performance with tools like Prometheus, Grafana, or Seldon Core to detect and address issues proactively.
6. Scalability Patterns
In addition to best practices, certain design patterns are commonly used to build scalable ML architectures.
Patterns:
Data Sharding: Split data into smaller, manageable chunks to distribute processing load.
Horizontal Scaling: Add more instances of a service to handle increased load rather than scaling up a single instance.
Caching: Use caching mechanisms (e.g., Redis, Memcached) to reduce latency and improve response times for frequently accessed data.
Serverless Architectures: Utilize serverless computing (e.g., AWS Lambda, Google Cloud Functions) for on-demand scaling of functions and services.
Recommended Resources
To deepen your understanding and implementation of scalable ML architectures, consider exploring these books and papers:
Books:
"Building Machine Learning Powered Applications" by Emmanuel Ameisen
"Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow" by Aurélien Géron

Papers:
"Machine Learning: The High Interest Credit Card of Technical Debt" by D. Sculley et al.
"Scaling Machine Learning at Uber with Michelangelo" by Jeremy Hermann and Mike Del Balso
"TensorFlow Serving: Flexible, High-Performance ML Serving" by Noah Fiedel
Conclusion
Building scalable ML architectures is a multifaceted challenge that requires careful consideration of various components and practices. By decoupling services, leveraging distributed computing, managing data efficiently, optimizing model training, and deploying robust monitoring mechanisms, you can ensure your ML systems are prepared to scale seamlessly. Embracing best practices and scalability patterns will empower your organization to handle growing demands and unlock the full potential of machine learning.
If you liked this newsletter, check out my upcoming courses:
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML and Causal Inference, to drive product growth.
AI/ML Projects for Data Professionals
Gain hands-on experience and build a portfolio of industry AI/ML projects. Scope ML Projects, get stakeholder buy-in, and execute the workflow from data exploration to model deployment. You will learn to use coding best practices to solve end-to-end AI/ML Projects to showcase to the employer or clients.
[Coming Soon] Machine Learning Engineering Bootcamp
Learn the intricacies of designing and implementing robust machine learning systems. This course covers essential topics such as ML architecture, data pipeline engineering, model serving, and monitoring. Gain practical skills in deploying scalable ML solutions and optimizing performance, ensuring your models are production-ready and resilient in real-world environments.
 | A guest post by
|