

Building your own Recommender System - Part 4/4
Discover the power of collaborative filtering in recommender systems! Learn how user-based and item-based approaches harness collective preferences to deliver smarter recommendations.

👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams.
This is Part 4 of our ongoing "Building Your Own Recommender Systems" series in collaboration with
! In the first three blogs, we explored the fundamentals of recommender systems:Part 1: Introducing of recommender systems and high-level architecture
Part 2: Evaluating recommender systems, focusing on metrics that assess their effectiveness.
Part 3: Building a content-based recommender system, a foundational approach that uses item attributes to make personalized recommendations.
Now, in Part 4, we shift our focus to collaborative filtering, one of the most widely used and effective techniques in recommender systems. Unlike content-based methods, collaborative filtering leverages user-item interactions to uncover patterns and preferences, enabling recommendations based on the wisdom of the crowd. We'll explore its two main types—user-based and item-based collaborative filtering—and discuss their strengths, challenges, and implementation.

In this part, weI dive deeper into building Collaborative Filtering Recommender Systems using the powerful Surprise library, explore User-Based and Item-Based Collaborative Filtering, and evaluate Matrix Factorization techniques like SVD for building robust recommendation systems.
Introduction to the Surprise Library
Surprise is a specialized Python library tailored for recommendation systems, offering a suite of algorithms and tools designed for researchers and practitioners.
Key Advantages of Surprise:
Ease of Use: Intuitive API to experiment with various recommendation algorithms.
Algorithm Variety: Includes Collaborative Filtering (User/Item-based), SVD, SVD++, NMF, Slope One, and KNN-based methods.
Built-in Metrics: Provides RMSE, MAE, and F1-score for model evaluation.
Cross-Validation: Simplifies robust model evaluation.
Data Loading: Supports built-in and custom datasets with preprocessing tools.
User-Based Collaborative Filtering
Initial Setup and Evaluation
Using Surprise, we’ll implement User-Based Collaborative Filtering with a focus on improving model accuracy. Here's the workflow:
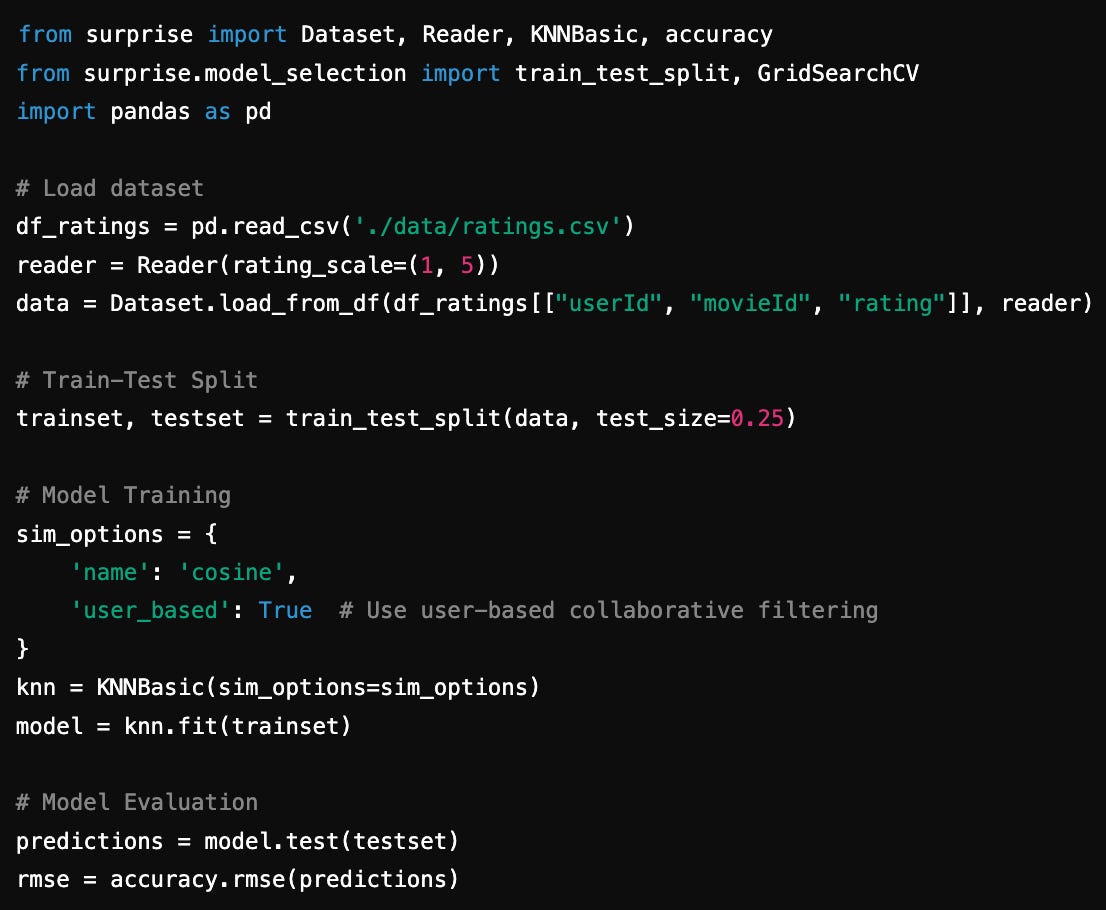
Initial Results:
RMSE: 0.9877
Average ratings in the dataset: 3.54
Conclusion: The RMSE is high, suggesting scope for improvement.
Hyperparameter Tuning with GridSearchCV To reduce RMSE, we tune hyperparameters like k, similarity metrics, and min_support.
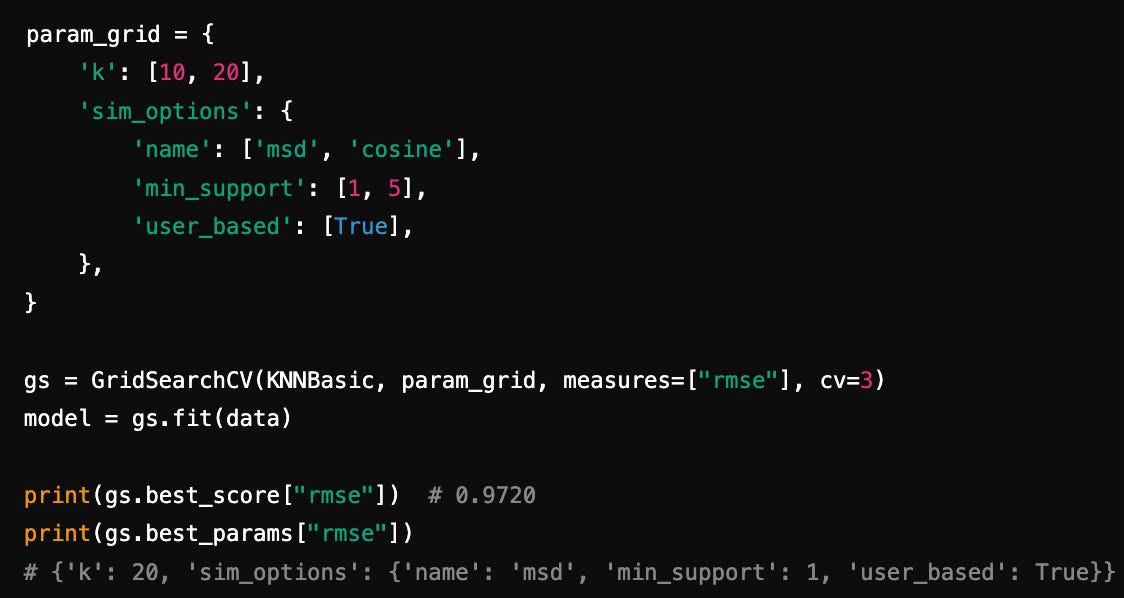
The chosen hyperparameters yields us a slightly better output of 0.9720.
We can then train the model using best parameters and get our Top N recommendations. Let’s take userId = 85 and create Top 10 recommendations for him based on similar users’ preferences.
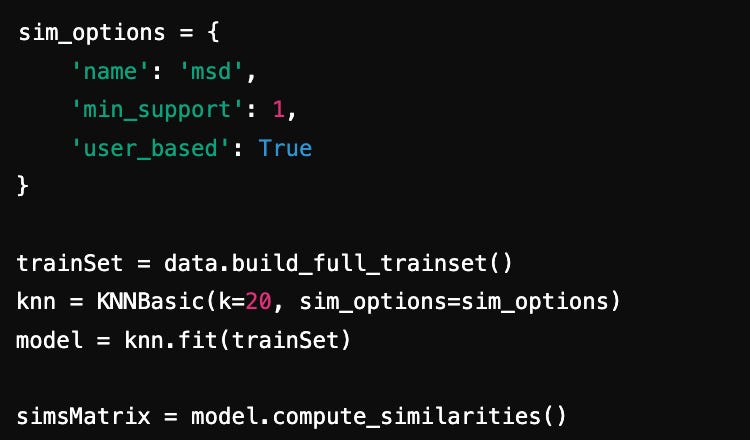

Observation: The recommendations align with User 85's preferences for action, adventure, and drama genres.
Item-Based Collaborative Filtering
The process for item-based collaborative filtering is similar but focuses on item similarities.
Initial Evaluation:
RMSE: 0.9959
After tuning: RMSE: 0.9514

While the tuned model improves, the recommendations do not seem as convincing compared to user-based filtering.
Matrix Factorization with SVD
Matrix factorization is a popular technique for model-based collaborative filtering. It decomposes the user-item rating matrix into two lower-rank matrices, representing latent user features and item features. The Surprise package provides several matrix factorization-based algorithms for recommender systems. Here are the main ones:
SVD (Singular Value Decomposition):
This is a classic matrix factorization technique that decomposes the user-item rating matrix into three matrices: user factors, item factors, and singular values. It's a basic algorithm that can be used as a starting point for more complex models.
SVD++:
An extension of SVD that incorporates implicit feedback (e.g., viewing history, purchases) into the model. It considers both explicit ratings and implicit signals to improve recommendation accuracy.
Shameless plug:
Learn the intricacies of designing and implementing robust machine learning systems. This course covers essential topics such as ML architecture, data pipeline engineering, model serving, and monitoring. Gain practical skills in deploying scalable ML solutions and optimizing performance, ensuring your models are production-ready and resilient in real-world environments.
NMF (Non-negative Matrix Factorization):
Similar to SVD, but it imposes non-negativity constraints on the factor matrices. This can lead to more interpretable results, as the factors represent positive contributions to ratings.
PMF (Probabilistic Matrix Factorization):
A probabilistic approach to matrix factorization that treats the rating prediction as a probabilistic process. It introduces regularization to prevent overfitting and improve generalization.
These algorithms are all implemented in the Surprise package and can be easily used for building recommender systems. You can experiment with different algorithms and hyperparameters to find the best model for your specific dataset and use case.
How SVD works:
User-Item Rating Matrix: This matrix represents the ratings given by users to items. Each row corresponds to a user, and each column corresponds to an item.
Matrix Decomposition: The user-item rating matrix is decomposed into two lower-rank matrices:
User Matrix (U): Represents latent features of users. Each row corresponds to a user, and each column represents a latent feature.
Item Matrix (V): Represents latent features of items. Each row corresponds to an item, and each column represents a latent feature.
The idea is that the dot product of a user's latent feature vector and an item's latent feature vector approximates the user's rating for that item. You can then use selected features (dimensionality reduction) from these vectors to predict user’s ratings accurately w/o much loss of information.
Mathematical Representation:
Let R be the user-item rating matrix, U be the user matrix, and V^T be the transpose of the item matrix.
R = U * V^T
Singular Value Decomposition (SVD):
SVD is a popular technique for matrix factorization. It decomposes a matrix into three matrices:
R = U * Σ * V^T
U: Orthogonal m×m matrix of left singular vectors of R
Σ: Diagonal m×n matrix of singular values of R
VT: Orthogonal n×n matrix of right singular vectors of R
By truncating the singular values and corresponding singular vectors, we can reduce the dimensionality of the original matrix and obtain a low-rank approximation. This low-rank approximation can be used to predict missing ratings in the user-item matrix.
Here is a python example to show how SVD works. Let’s see how we can break down a sample Ratings, R matrix into its eigenvalue and eigenvector components and re-create it back from those individual components.
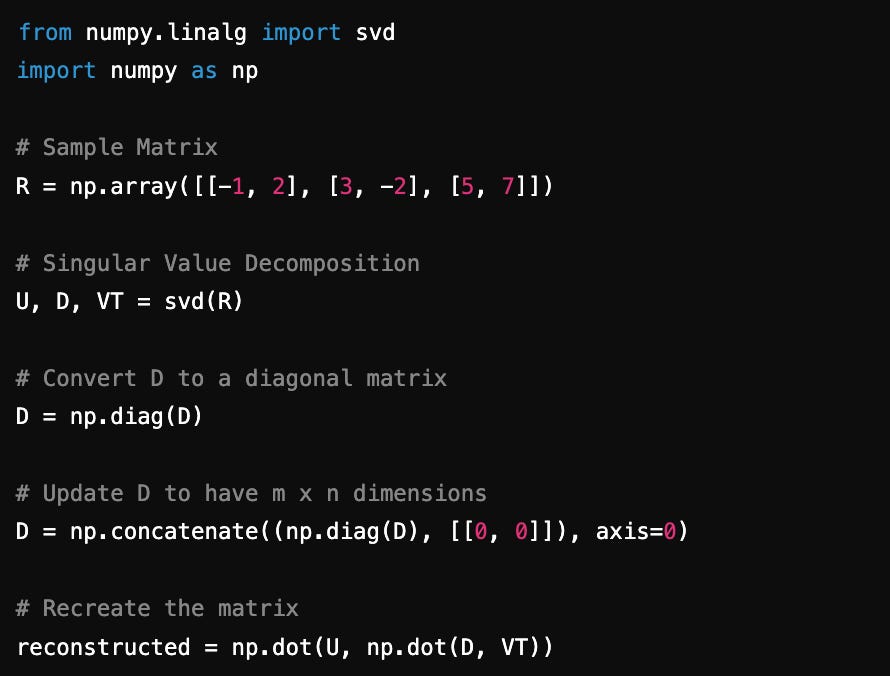
Having understood how SVD works, let’s look at its use in building recommender systems.

Initial run of SVD itself is very promising with RMSE of 0.8945. After hyperparameter tuning, RMSE drops to 0.8917. If you take a look at the code block below, you would notice a hyperparameter n_factors. This is the parameter that helps with dimensionality reduction. It helps us choose the most important latent features out of all the latent features that are in user and items feature matrices.
Now, let’s look at the Top 10 recommendations for user 85 once again. These recommendations are more or less similar to what we saw from user-based technique and personally, I feel it represents the users taste much better.

Closing Thoughts
In this part, we explored different algorithms:
User-Based Collaborative Filtering: High interpretability and decent accuracy.
Item-Based Collaborative Filtering: Slightly higher RMSE but less convincing recommendations.
Matrix Factorization (SVD): Best RMSE and highly scalable.

While offline metrics like RMSE provide useful insights, A/B testing remains critical to evaluate real-world impact. The field of recommender systems continues to evolve, with advancements in Deep Learning and Large Language Models (LLMs) paving the way for solving challenges like data sparsity and cold-start problems.
Recommender systems have become an essential tool for navigating the ever-growing sea of information and products available online. As we've seen, they can be implemented using various techniques, each with its strengths and weaknesses.
However, recommender systems are constantly evolving. Traditional methods like collaborative filtering and matrix factorization are powerful but often face challenges with data sparsity and cold start problems.
This is where advancements in deep learning and large language models (LLMs) come into play:
Deep Learning: Architectures like Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) can handle complex user-item interactions, enabling systems to extract deeper insights and offer more personalized, nuanced recommendations.
Large Language Models (LLMs): With their ability to process and generate human language, LLMs can transform recommender systems. By analyzing textual data such as reviews, descriptions, and user queries, they create a richer understanding of user preferences and item attributes, leading to context-aware and dynamic recommendations.
The future of recommender systems is bright, driven by these groundbreaking advancements. Deep learning and LLMs promise to deliver more personalized, contextual, and user-centric recommendations, ultimately enhancing the online experience for everyone.
As recommender systems continue to push the boundaries of innovation, I’m excited to explore these developments further. Stay tuned for future articles where I’ll delve deeper into these technologies and their transformative potential.
References
Building Recommender Systems with Machine Learning and AI, Udemy course by Frank Kane
Check out my upcoming courses:
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML and Causal Inference, to drive product growth.
AI/ML Projects for Data Professionals
Gain hands-on experience and build a portfolio of industry AI/ML projects. Scope ML Projects, get stakeholder buy-in, and execute the workflow from data exploration to model deployment. You will learn to use coding best practices to solve end-to-end AI/ML Projects to showcase to the employer or clients.
Machine Learning Engineering Bootcamp
Learn the intricacies of designing and implementing robust machine learning systems. This course covers essential topics such as ML architecture, data pipeline engineering, model serving, and monitoring. Gain practical skills in deploying scalable ML solutions and optimizing performance, ensuring your models are production-ready and resilient in real-world environments.
Not sure which course aligns with your goals? Send me a message on LinkedIn with your background and aspirations, and I'll help you find the best fit for your journey