

GHC 2025 Recap: Designing Robust Experiments
A recap of our GHC 2025 session on designing robust A/B tests — exploring how to move beyond statistical significance and build experiments that drive real business impact.


👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams.
Last week at Grace Hopper Celebration, I had the privilege of presenting on “Designing Robust A/B Tests” along with Banani Mohapatra to an audience of 500+ Product Managers and Data Scientists. We moved beyond the simplistic “p < 0.05” heuristic to explore how to design experiments that truly measure business impact.

Our discussion covered critical topics such as preventing Sample Ratio Mismatch (SRM), managing network effects, and the risks of repeated peeking. My sincere thanks to everyone who attended and contributed to such a dynamic session. GHC remains an unparalleled source of inspiration, bringing together the leaders and innovators shaping our industry’s future.
I’ve captured all the key insights and learnings from our session in this newsletter, so we can continue the conversation and share these ideas with a wider audience.
About the Speakers:
🔹 Banani Mohapatra — A seasoned data science product leader with 13+ years of experience across e-commerce, payments, and real estate. She currently leads a data science team for Walmart’s subscription product, driving growth while supporting fraud prevention and payment optimization. Known for translating complex data into strategic solutions that accelerate business outcomes.
🔹 Manisha Arora — A data science professional with 12+ years of experience leading teams and driving business growth through data-driven decision making. Passionate about democratizing data science and enabling others to level up in their careers.
1. The Foundation: Why Experimentation Matters
Experimentation is central to data-driven decision-making. It reduces the reliance on intuition and validates hypotheses with measurable outcomes before committing to large-scale rollouts. A strong experimentation culture enables teams to make informed, evidence-backed choices.
Industry examples such as Netflix’s “Top 10” feature and Bing’s color experiments demonstrated how rigorous A/B testing, when guided by clear goals and accurate measurement, can translate small interface tweaks into multimillion-dollar business impact.
2. Building a Culture of Continuous Learning
Effective experimentation functions as a continuous cycle of learning, execution, and refinement. A robust setup typically involves multiple disciplines working in harmony:
Product Management defines the business problem and hypothesis.
Data Science ensures the validity and interpretability of results.
Engineering safeguards randomization and data integrity.
Design and UX maintain the human experience throughout the process.
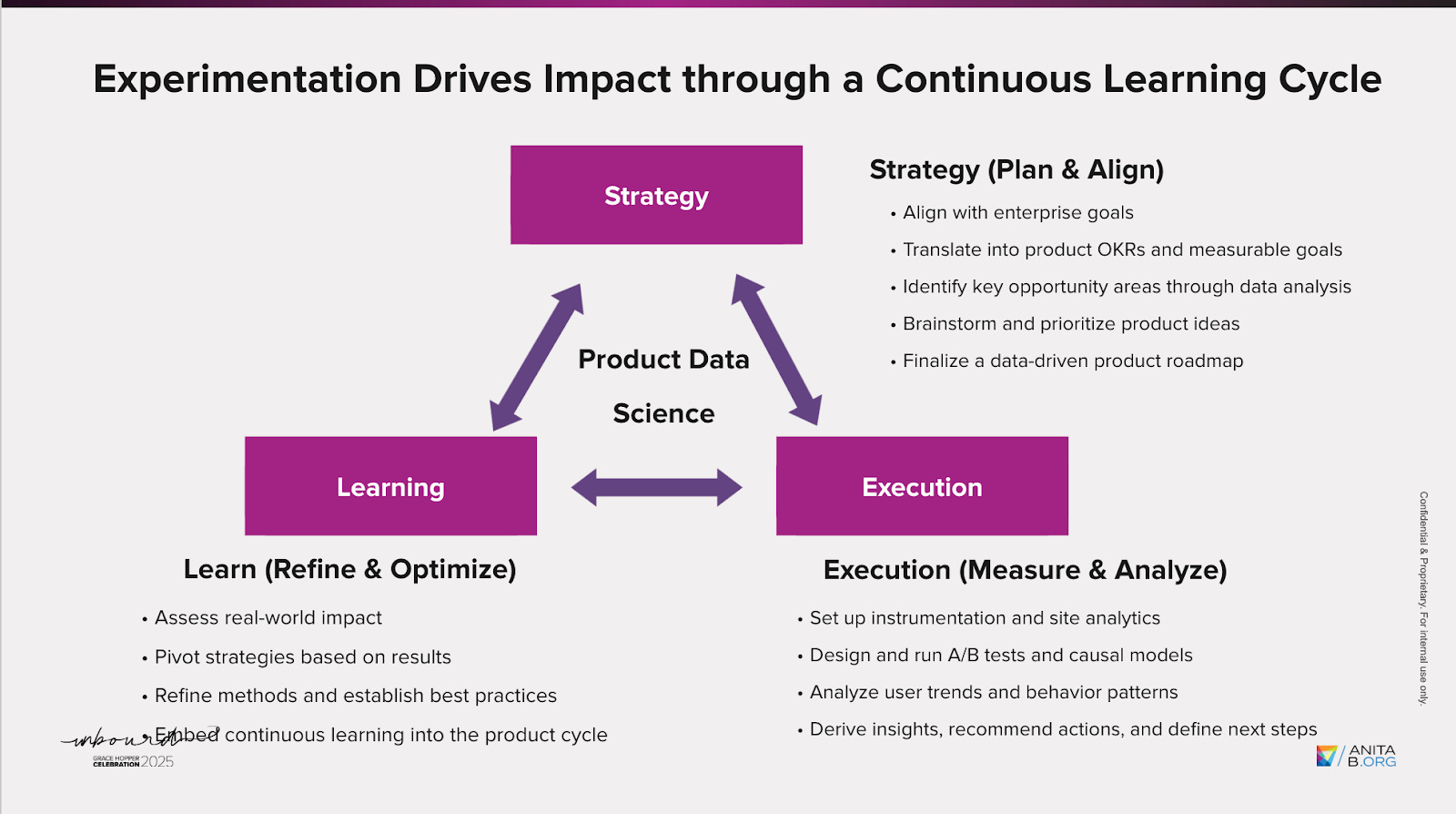
When collaboration across these roles is seamless, experimentation transforms from a validation mechanism into a strategic driver of innovation and growth.
3. Moving Beyond Statistical Significance
A common misconception in experimentation is treating a low p-value as proof of success. In reality, a p-value only measures how surprising a result is under the null hypothesis—it doesn’t confirm whether that result is meaningful or beneficial.
Combining p-values with confidence intervals provides better insight into the direction and magnitude of effects. This dual perspective helps ensure that conclusions reflect business relevance, not just mathematical significance.
4. Designing Robust Experiments
The quality of an A/B test depends heavily on its robustness. Several factors can silently compromise the validity of results:
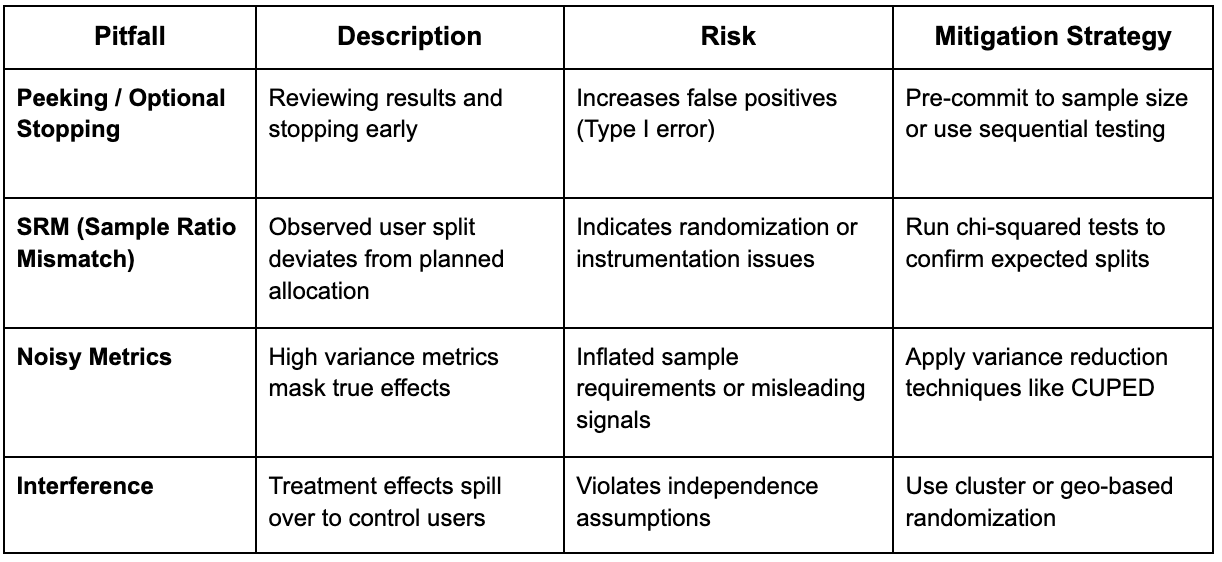
Anticipating and managing these pitfalls through thoughtful design and validation safeguards both the reliability and credibility of insights.
5. Learning from Inconclusive Results
In real-world experimentation, inconclusive outcomes are common—especially when confidence intervals overlap zero. Rather than labeling these as failures, such results can uncover valuable diagnostic information.
Key areas to assess include:
Adequacy of sample size and test duration
Subgroup-level variations
Relevance and sensitivity of chosen metrics
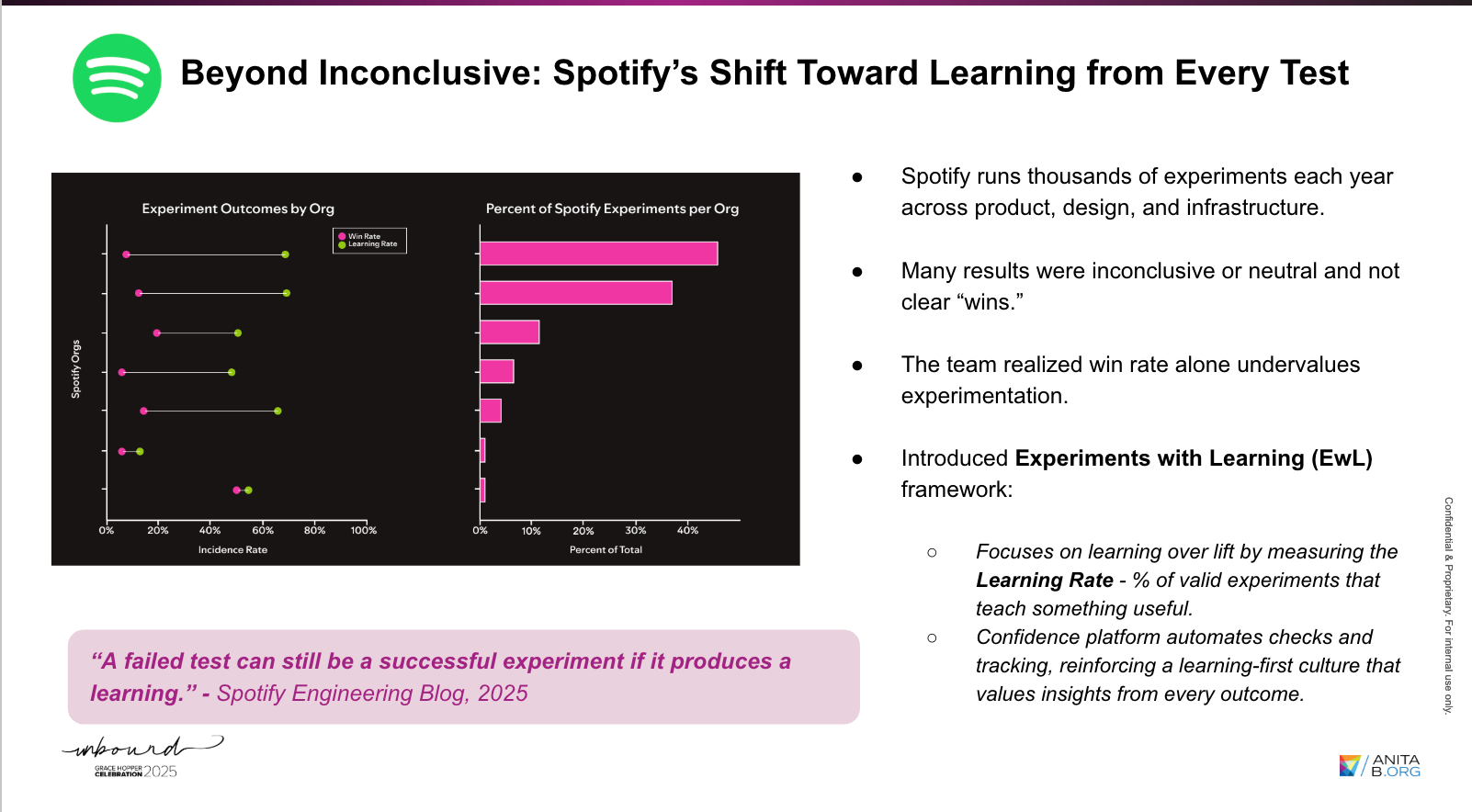
Organizations like Spotify have adopted a “Experiments with Learning (EwL)” framework that prioritizes the learning rate—the proportion of tests that generate actionable insights—over the win rate. This approach emphasizes progress over perfection.
6. Designing Intentional Experiments
Intentional experimentation begins with a clear, testable statement that connects user needs to measurable outcomes.
Here’s a template of a clear hypothesis:
“We believe that [user problem].
If [intervention] is introduced,
then [expected behavior] will occur,
resulting in [business impact].”
This structure aligns teams around a common goal and ensures that success metrics are defined upfront. Selecting primary and guardrail metrics is equally critical—optimizing one metric should never come at the cost of user experience or long-term value.
Cross-functional alignment between product managers, data scientists, designers, and engineers strengthens every stage of the experimentation lifecycle—from hypothesis design to post-test analysis—making it a true team discipline.
Key Takeaways

Closing Thought
The true value of experimentation lies not in validation but in discovery.
If there’s one takeaway I want you to walk away with, it has to be this:
Don’t test to prove. Test to improve.
That mindset shifts experimentation from a statistical exercise to a catalyst for growth, clarity, and innovation.
I had an incredible time at the conference — especially the conversations with Product Managers and Data Scientists from Amazon, Capital One, LinkedIn, and many others. Those exchanges were insightful and taught me so much!
A huge thank you to Banani for being such a fantastic partner throughout this journey, and to the GHC team for organizing an event that continues to create space and amplify voices of women in tech.
If you’d like to dive deeper into experimentation, here are a few of our learning programs you might enjoy:
A/B Testing Course for Data Scientists and Product Managers
Learn how top product data scientists frame hypotheses, pick the right metrics, and turn A/B test results into product decisions. This course combines product thinking, experimentation design, and storytelling—skills that set apart analysts who influence roadmaps.
Advanced A/B Testing for Data Scientists
Master the experimentation frameworks used by leading tech teams. Learn to design powerful tests, analyze results with statistical rigor, and translate insights into product growth. A hands-on program for data scientists ready to influence strategy through experimentation.
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML, and Causal Inference, to drive product growth.
Not sure which course aligns with your goals? Send me a message on LinkedIn with your background and aspirations, and I’ll help you find the best fit for your journey.
 | A guest post by
|