

Operating Under Ambiguity: Senior Data Scientist vs Staff Data Scientist
The hardest transition in Data Science from Senior to Staff isn’t technical, it’s learning to navigate unclear problems, conflicting stakeholders, and decision-driven ambiguity.

I’ve sat across from some of the sharpest data scientists I’ve ever met people with rigorous technical instincts, strong reviews, and a genuine track record of shipping work that mattered and watched them hit the same invisible wall.
The feedback they get is always some version of the same thing:
“Your technical work is excellent. We just need to see you operating at a higher level.”
They nod. They go back to their desks. They work harder, run more thorough analyses, write cleaner code.
And six months later, they’re having the same conversation.
I know this pattern because I’ve been in both rooms. I’ve been the data scientist wondering what “higher level” actually means in practice. And I’ve been in calibration sessions where that phrase gets used — and where nobody, including me, always had a clean answer for what it would take to get there.
So let me try to give you the answer I didn’t have then.
👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams.
The Gap No One Talks About:
The standard career advice about ambiguity goes something like this: get comfortable with it. Embrace it. Lean in.
This advice isn’t wrong. It’s just not useful. It describes a destination without giving you a map.
Here’s what actually separates Senior from Staff data scientists in ambiguous situations: Senior DSs are optimizing to minimize errors. Staff DSs are optimizing to minimize the cost of delayed decisions. Those are different objective functions entirely, and nobody tells you the function changed.
At the Senior level, you’ve been trained — in school, in early jobs, in every performance review — to take a well-formed question and produce a rigorous answer. That is genuinely hard. Most people can’t do it well. The problem is that at Staff level, the questions stop being well-formed. Stakeholders don’t hand you a target variable and a success metric. They hand you a symptom, a worry, or a vague strategic goal — and they’re counting on you to figure out what question is actually worth asking. This isn’t just a harder version of the same job. It’s a different job.
This isn’t just a different degree of difficulty. It’s a different type of work entirely.
And here’s the part that makes it particularly hard to navigate: the feedback loop for getting this right is long and indirect. When you build a great model, you know within weeks whether it worked. When you correctly frame an ambiguous problem, the payoff might show up in a roadmap decision three months later — attributed to a meeting you influenced, not an analysis you shipped. The work becomes less legible precisely when it becomes more important.
Why Smart People Stay Stuck
There’s a specific failure pattern I’ve watched play out across companies of every size — and it almost always looks the same.
A VP sends a message: “We’re losing customers. Can you help us understand what’s going on?”
The Senior DS opens a notebook. Two weeks later, they come back with a thorough metric decomposition — churn by segment, by cohort, by acquisition channel. The slide deck is clean. The methodology is solid. The VP says “this is really helpful” — and nothing happens.
The analysis wasn’t wrong. The question was.
The Senior DS answered what happened. The VP needed to make a decision about what to do next — probably between two strategic options that were already on the table. Those are different problems, and building a beautiful answer to the first one doesn’t help you make the second one.
I’ve been in that room. I’ve built that deck. And I’ve felt the particular frustration of doing genuinely good work that doesn’t move anything.
What I’ve come to understand is that the failure usually happens before the first line of code is written. It happens in the thirty seconds when you receive an ambiguous request and — because you’ve been rewarded your whole career for getting to answers quickly — you start thinking about solutions before you’ve interrogated the question.
The most expensive mistake in data science isn’t a bad model. It’s a brilliant answer to the wrong question.
The Actual Structure of Ambiguity (and Why It Comes in Different Forms)
Here’s something that took me longer than it should have to understand: not all ambiguity is the same. Treating it as one undifferentiated thing — something to either push through or wait out — is one of the most consistent failure modes I’ve seen at the Senior-to-Staff transition.
There are roughly three types of ambiguity you’ll encounter in practice:
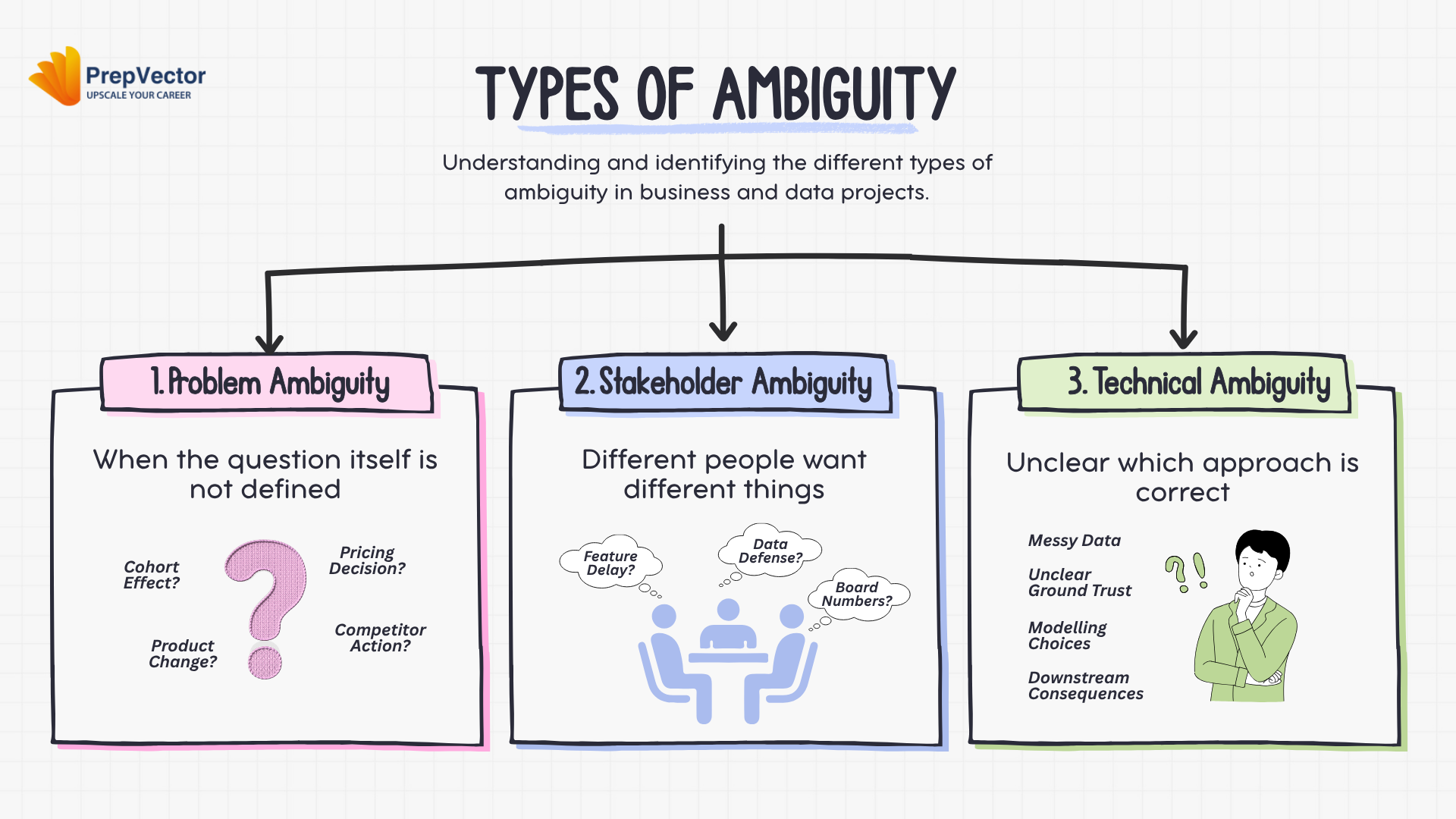
Problem ambiguity is when the question itself isn’t well defined. “Why is churn going up?“ sounds like a question. It’s actually a symptom statement. The real question might be about a product change, a pricing decision, a competitor action, or a cohort effect — each of which points to a completely different analysis and a completely different decision. Accepting the symptom as the question is where most analyses go wrong before they start.
Stakeholder ambiguity is when different people in the room want different things from the same work — and nobody has made the conflict explicit. I’ve seen this more times than I can count at Google: the VP of Product wants data that supports slowing a feature rollout. The VP of Engineering wants data that defends their implementation choices. The finance lead wants a number for a board deck. They’ve all asked their respective questions, but they’re not asking the same question. If you don’t surface this early, here’s what happens — you deliver good work, and it disappears. Not because it was wrong. Because it landed in the middle of a conflict nobody named.
Technical ambiguity is when you don’t know which approach is right because the data is messy, the ground truth is unclear, or the modeling choices have genuine downstream consequences that aren’t separable from the business question. This is the type most data scientists are most comfortable with — which is probably why it gets the most attention.
Resolving problem ambiguity requires forcing a prioritization conversation. Resolving stakeholder ambiguity requires making the conflict visible — diplomatically, but directly. Resolving technical ambiguity is largely the domain of craft.
Senior data scientists are excellent at technical ambiguity. Staff data scientists learn to operate across all three simultaneously — and more importantly, they’ve learned to diagnose which one they’re actually dealing with before choosing their response.
A Working Framework for Moving Through It
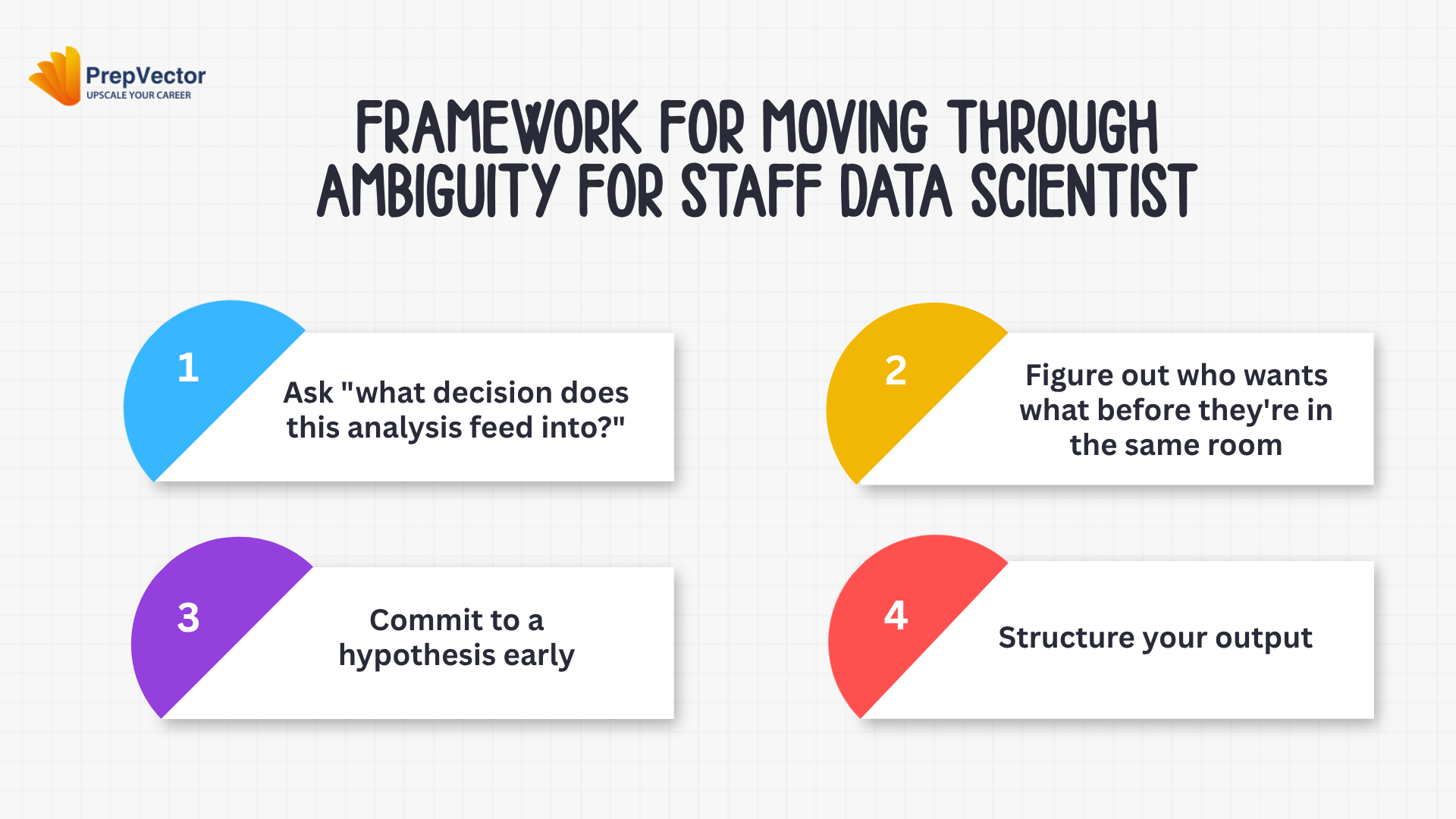
This isn’t a flowchart. Organizations are too messy for flowcharts. But there is a sequence of questions that tends to cut through ambiguity faster.
Step 1: Ask “what decision does this analysis feed into?”
Every analytical request is downstream of a decision someone needs to make. The problem is that the question as stated “why is churn up?” or “is this feature working?” is rarely that decision. It’s a symptom of it.
Before writing a single query, ask yourself: if I answer this perfectly, what actually happens next? Who acts on it, and how?
If you can’t answer that, you’re not missing data. You’re missing context. Go get the context first.
Step 2: Figure out who wants what before they’re in the same room.
In most ambiguous situations, the fog isn’t technical. It’s political. Different teams have different stakes in the outcome, different definitions of success, and different interpretations of what the data “should” show. Nobody announces this. But it shapes everything.
If you don’t surface this early, here’s what happens: you deliver good work, and it disappears. Not because it was wrong. Because it landed in the middle of a conflict nobody named, and both sides quietly discredited it.
So before the analysis starts, have short individual conversations with key stakeholders to know what you’re walking into.
When there’s a real tension between what two stakeholders want, you have two choices. Name it directly “I’m noticing Product and Engineering are measuring success differently here, and I want to flag that before I go too deep” or factor it into your framing and make your assumptions explicit.
Step 3: Commit to a hypothesis early
The most common failure mode in ambiguous analytical work isn’t bad methodology. It’s the analysis that never ships because it’s never quite done. There’s always one more cut to run, one more data quality issue to resolve, one more stakeholder to align.
Staff-level work requires a different discipline: form a directional hypothesis early, state it explicitly, and then try to break it. Not “here’s what I think the answer might be” but “my current best guess is X, and here’s specifically what would have to be true for me to be wrong.”
This does two things. It focuses on analysis instead of exploring everything. And it makes your reasoning legible to others, which matters when you need to move fast or loop in stakeholders mid-stream.
The trap to avoid is dressing up indecision as rigor. If you’re two weeks into an investigation and still can’t state a directional hypothesis, the problem usually isn’t the data. It’s that the question was never well-formed to begin with which takes you back to Step 1.
Step 4: Structure your output
Senior-level communication typically has one calibration: the most technical person likely to read it. That’s not wrong but it’s insufficient at Staff level.
In most organizations, the same piece of analytical work needs to serve an executive who needs a clear recommendation, a PM or business partner who needs to understand the implications for their roadmap, and a technical peer who needs to trust the methodology.
The practical discipline: before you finalize any significant output, ask yourself whether someone who didn’t attend any of the scoping meetings could read it and know what to do next. Not just what you found what they should do. If the answer is no, the communication isn’t done yet, regardless of whether the analysis is.
The risk in ambiguous situations is rarely that people misunderstand the math. It’s that they understand the math and still leave the room without a decision. That gap is yours to close.
The Honest Reality
I want to say something that doesn’t always make it into career advice articles, because it’s uncomfortable.
In large tech companies especially, the ambiguity you’re navigating is often more political than analytical. The data exists. The question is who controls the narrative. The ability to understand incentive structures, build coalitions, and position findings strategically matters as much as any technical skill.
I know that’s not what many of us signed up for. A lot of data scientists chose this field because it felt more meritocratic than that — more grounded in evidence, less shaped by who’s in the room. And in some ways, it is. But at the Staff level, you’re in the room. And what happens in the room matters.
Leadership expectations also vary significantly. Some managers want you to come in with a point of view and defend it. Others want you to present options and let them decide. Some want you to make the problem go away; others want to stay closely involved. Reading this accurately and adapting without losing your own judgment is a required skillset for Staff Data Scientist
Takeaways:
The transition from Senior to Staff is often described as a promotion. I think it’s more accurate to call it a re-orientation.
Senior data scientists optimize within the problem space. Staff data scientists define what the problem space is. That distinction sounds small. The gap in practice is enormous.
The good news: it’s learnable. It doesn’t require a different personality or a different career. It requires a deliberate shift in where you focus your attention — from the model to the question behind the model, from the analysis to the decision the analysis is meant to unlock.
If you’d like to dive deeper into experimentation, here are a few of our learning programs you might enjoy:
Causal Inference Weekend Course
Learn how leading data scientists move beyond correlation and use causal reasoning to drive better business and product decisions. This course covers the full causal toolkit from Difference-in-Differences and Regression Discontinuity to Propensity Score Matching, Instrumental Variables, and Double Machine Learning so you can produce analyses that are credible, defensible, and decision-ready.
Master Product Sense and AB Testing and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML, and Causal Inference, to drive product growth.
Not sure which course aligns with your goals? Send me a message on LinkedIn with your background and aspirations, and I’ll help you find the best fit for your journey.