
ReAct (Reason + Action) AI Agents
Learn how to create ReAct agents that use reasoning and actions to interact with the world. I'll guide you through the process of building your own intelligent agent.


👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams
Introduction
So far, I have shown you how AI chatbots work with RAG & memory. Forget just retrieving information; what if you could build a real-time Reasoning + Actioning (ReAct) AI chatbot that streams their thoughts, actions and answers in response to your questions?
In this post, I'll show you how to build a ReAct chatbot – an AI that doesn't just answer your questions but also shows you its thinking process and is capable of utilizing different tools! You will learn why ReAct is a game-changer, and how you can start building more transparent and capable AI agents. So, are you ready to unlock the power of reasoning in your AI? Let's get started!
Note - For those seeking to build this application themselves after reading the post, you can find the complete code in this GitHub repo.
About the Authors:
Arun Subramanian: Arun is an Associate Principal of Analytics & Insights at Amazon Ads, where he leads development and deployment of innovative insights to optimize advertising performance at scale. He has over 12 years of experience and is skilled in crafting strategic analytics roadmap, nurturing talent, collaborating with cross-functional teams, and communicating complex insights to diverse stakeholders.
Manisha Arora: Manisha is a Data Science Lead at Google Ads, where she leads the Measurement & Incrementality vertical across Search, YouTube, and Shopping. She has 12 years experience in enabling data-driven decision making for product growth. Manisha is the founder of PrepVector that aims to democratize data science through knowledge sharing, structured courses, and community building.
What is ReAct?
"ReAct” stands for 'Reasoning and Acting'. It's a technique that allows AI agents to generate both verbal reasoning traces and actions to interact with an environment. Instead of just giving a direct answer, the AI thinks out loud, deciding what it needs to do (search the web, look up a paper, etc.) and then acts on that thought. This approach makes the AI more transparent, reliable, and capable of handling complex tasks. It's a big leap from traditional chatbots that often give simple, canned responses.

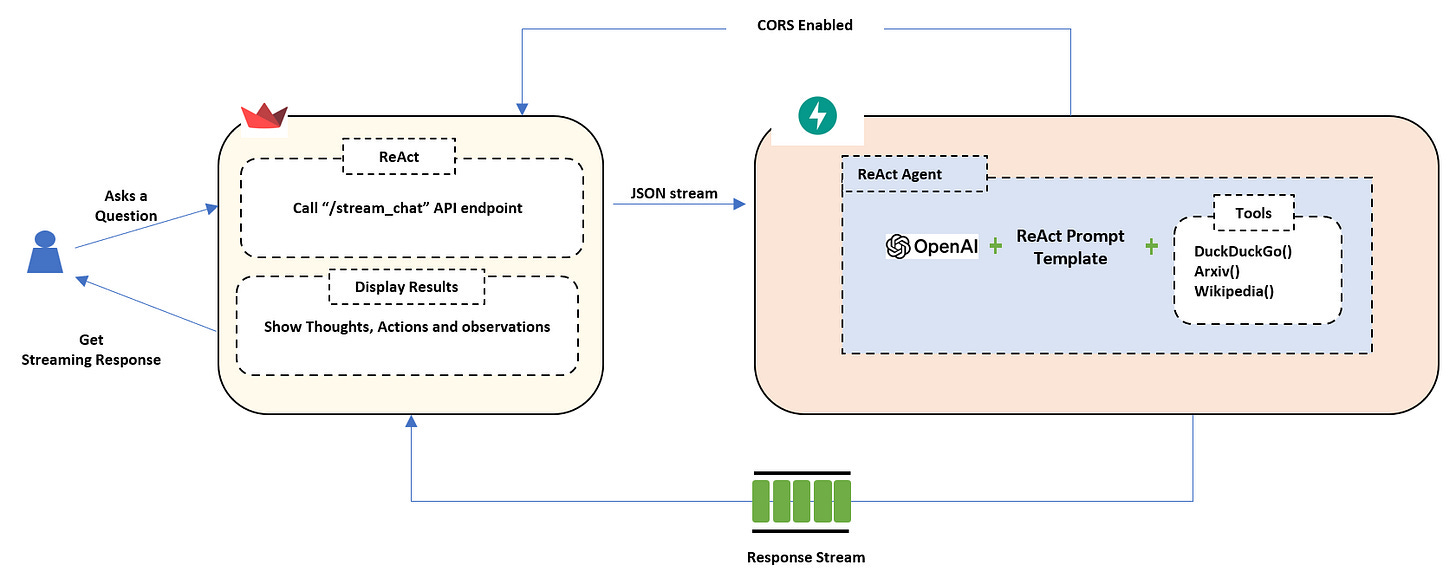
High level Architecture
Let's break down how this ReAct chatbot works, from the moment you ask a question to the moment you get an insightful answer. It involves a combination of smart AI, helpful tools, and smooth communication between different parts of the system.
Backend Power: FastAPI and LangChain
The backend of the application, built with FastAPI, is where the AI's heavy lifting happens. Here are the key components:
LLM (Large Language Model): OpenAI's gpt-3.5-turbo serves as the "brain". It processes your questions, generates the AI's thoughts and decides which tools to use.
ReAct Prompt Template: This is a carefully crafted set of instructions that guides the LLM on how to use the ReAct framework, format its thoughts and actions, and provide a final answer. You can find more such standardized templates for use in https://smith.langchain.com/hub/
Tools: To make the AI even more helpful, it has access to several tools:
Search: DuckDuckGo Search Run is used for general web searches.
Wikipedia: Wikipedia Query Run helps in looking up information on Wikipedia.
Arxiv: Arxiv Query Run is used to find research papers.
# LLM setup
llm = ChatOpenAI(api_key=OPENAI_API_KEY,
model="gpt-3.5-turbo",
temperature=0,
streaming=True,
)
# Tools setup
arxiv_wrapper = ArxivAPIWrapper(top_k_results=2, doc_content_chars_max=1000)
arxiv = ArxivQueryRun(api_wrapper=arxiv_wrapper)
wiki_wrapper = WikipediaAPIWrapper(top_k_results=2, doc_content_chars_max=1000)
wiki = WikipediaQueryRun(api_wrapper=wiki_wrapper)
search = DuckDuckGoSearchRun()
tools = [
Tool(name="Search", func=search.run, description="Useful for general web searches."),
Tool(name="Wikipedia", func=wiki.run, description="Useful for looking up information on Wikipedia."),
Tool(name="Arxiv", func=arxiv.run, description="Useful for searching academic papers on arXiv."),
]
# Define the prompt template for the Deep Learning tutor
prompt = hub.pull("hwchase17/react")
# Setup a ReAct Agent
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent =agent,
llm=llm,
tools=tools,
prompt=prompt,
verbose=True,
)Frontend Magic: Streamlit and Streaming Responses
The frontend, built with Streamlit, provides a user-friendly interface for interacting with the chatbot.
Streaming Responses: FastAPI sends the chatbot's response in chunks using StreamingResponse. This means you see the answer and the AI's thought process in real-time, making the interaction feel more dynamic.
Streamlit receives these chunks and displays them as they arrive. Each chunk might contain an action the AI took (e.g., a search query) or a piece of the final answer.
`# Stream the response from FastAPI
for response_chunk in get_streaming_response(query):
if isinstance(response_chunk, dict) and "output" in response_chunk:
st.session_state.full_response += str(response_chunk["output"])
else:
st.session_state.full_response += str(response_chunk)
st.session_state.messages.append({"role": "assistant",
"content": response_chunk})
response_container.write(st.session_state.full_response)Bridging the Gap: CORS
CORS (Cross-Origin Resource Sharing) is crucial for allowing communication between the frontend (Streamlit, running in your browser) and the backend (FastAPI, running on a server).
Since the frontend and backend often run on different origins (domains, ports, or protocols), browsers restrict direct communication for security reasons.
CORS acts as a bridge, with the FastAPI backend specifying which origins are allowed to access its resources. This is done using the CORSMiddleware
If you remember, we didn’t worry much about CORS in our previous blog posts since we dealt with simple GET and POST requests which the browser might allow by default. Streaming makes CORS absolutely necessary to tell the browser that the cross-origin communication between Streamlit and FastAPI is intentional and allowed.
app = FastAPI(title="Langchain Server",
version="1.0",
description="A simple API server using Langchain")
origins = ["http://localhost:8501", "http://127.0.0.1:8501"]
app.add_middleware(CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"])Bringing It All Together: The Chatbot Flow
Here's how all these pieces work together:
You ask a question in the Streamlit app.
Streamlit streams your question to the FastAPI backend.
FastAPI receives the question and the LLM processes it using the ReAct prompt and available tools.
The LLM generates a series of thoughts and actions, using tools as needed.
FastAPI streams these thoughts, actions, and the final answer back to Streamlit.
Streamlit displays the streaming response to you in real-time.
This architecture allows for a powerful and interactive chatbot experience, where the AI not only answers questions but also demonstrates its reasoning process.
A Test Drive: Seeing the ReAct Chatbot in Action
Ready to see this ReAct chatbot in action? Let's take it for a spin and observe how it tackles a question.
Example Question: Give me the most famous dialogues from the movie ‘The Matrix’?
This is a simple question that you can do Google search on, scroll through different pages and come up with a summarized list of famous dialogues. Let’s see how ReAct chatbot handles it step by step.
The Chatbot's Thought Process (as revealed by the streaming output):
Thought: I should search for information on famous dialogues from the movie The Matrix.
Action : It uses the Search tool with the query “Famous dialogues from The Matrix movie”
I have currently not captured the interim search results as “Observations” in my prototype to keep things simple. However, if I had done it, you would have noticed that the initial results are not satisfactory.
Thought : I should look for a specific list of famous dialogues from the The Matrix movies.
Action : AI Agent rephrases its Search keywords automatically to get better responses
After going through the Thought → Action → Observation → Thought loop a couple of times, it finally decides it is ready for the answer. Take a look at this entire process in the screenshot below

Conclusion
You saw how the ReAct chatbot showed us its reasoning:
It broke down the complex question into smaller steps.
It used different tools strategically (Search, Wikipedia and Arxiv).
It combined information from multiple sources to give a comprehensive response.
This is the power of ReAct! It allows the AI to "think" its way through problems, leading to more reliable and informative answers.
Try It Yourself!
I encourage you to try out the chatbot with your own questions. See how it handles complex inquiries and what its thought process looks like. It's a fascinating way to see AI in action!
Upcoming Courses:
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML, and Causal Inference, to drive product growth.
AI/ML Projects for Data Professionals
Gain hands-on experience and build a portfolio of industry AI/ML projects. Scope ML Projects, get stakeholder buy-in, and execute the workflow from data exploration to model deployment. You will learn to use coding best practices to solve end-to-end AI/ML Projects to showcase to the employer or clients.
Not sure which course aligns with your goals? Send me a message on LinkedIn with your background and aspirations, and I'll help you find the best fit for your journey.
 | A guest post by
|