



Unveiling Michelangelo: Democratization of ML across Uber – Part 1/2
Discover how Uber's Michelangelo platform revolutionizes machine learning at scale, enabling seamless deployment and management and democratizing machine learning across Uber.


👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams.
In the rapidly evolving world of ride-sharing and food delivery, Uber has consistently pushed the envelope with innovative technology. At the heart of this innovation lies Michelangelo, Uber’s in-house machine learning platform. Built to scale, Michelangelo is designed to democratize machine learning across Uber, enabling teams to deploy complex models with ease. In this post, we will dive into the core components of Michelangelo, its architecture, and the impact it has had on Uber's operations.
Motivation behind Michelangelo
Before Michelangelo, Uber struggled with the fragmented process of building and deploying machine learning models, hindered by the scale of its operations. Data scientists used diverse tools like R and scikit-learn, while engineers developed custom systems for deploying models, resulting in limited ML impact. The lack of standardized pipelines for training and prediction data, coupled with difficulties in training models beyond desktop capacities and inconsistent deployment practices, highlighted the need for a more cohesive solution.
Michelangelo was developed to address these challenges by providing an end-to-end system that standardized workflows across teams, enabling scalable and efficient ML operations. Initially focused on scalable model training and production deployment, the platform later evolved to enhance feature pipeline management and developer productivity, ensuring that Uber's ML capabilities could grow alongside its business.
Journey of Michelangelo 1.0
In early 2016, Michelangelo was launched to standardize the ML workflows via an end-to-end system that enabled ML developers across Uber to easily build and deploy ML models at scale. It started by addressing the challenges around scalable model training and deployment to production serving containers (Learn more). Then, a feature store named Palette was built to better manage and share feature pipelines across teams. It supported both batch and near-real-time feature computation use cases. Currently, Palette hosts more than 20,000 features that can be leveraged out-of-box for Uber teams to build robust ML models (Learn more).
Other key Michelangelo components released include, but are not limited to:
Gallery: Michelangelo’s model and ML metadata registry that provides a comprehensive search API for all types of ML entities. (Learn more)
Manifold: A model-agnostic visual debugging tool for ML at Uber. (Learn more)
PyML: A framework that speeded up the cycle of prototyping, validating, and productionizing Python ML models. (Learn more)
Extend Michelangelo’s model representation for flexibility at scale. (Learn more)
Horovod for distributed training. (Learn more)
Machine Learning Workflow in Michelangelo
The Machine Learning (ML) workflow at Uber, facilitated by Michelangelo, is designed to be robust, scalable, and flexible enough to handle a wide variety of ML use cases, including but not limited to classification, regression, and time series forecasting. This workflow is implementation-agnostic, making it adaptable to new algorithms and frameworks as they emerge. Additionally, it is versatile enough to support different deployment modes, whether for online predictions with low latency requirements or offline batch processing.

Michelangelo's architecture is built to streamline and optimize each stage of this workflow. Below, we delve into the specific details of how Michelangelo supports each of the six primary stages of the ML workflow: Data Management, Model Training, Model Evaluation, Model Deployment, Making Predictions, and Monitoring.
1. Data Management
Feature Engineering and Pipeline Management
Data management is foundational in ML, and Michelangelo places a significant emphasis on creating scalable, reliable, and reproducible data pipelines. The creation of high-quality features often represents one of the most challenging and time-consuming aspects of the ML process. Michelangelo addresses this challenge by providing tools that integrate deeply with Uber’s data ecosystem, including its data lakes and real-time data sources.
Michelangelo's data management system is divided into two primary pipelines:
Offline Pipelines:
HDFS Integration: Uber’s transactional and log data is funneled into a Hadoop Distributed File System (HDFS) data lake, making it accessible for large-scale data processing through Spark and Hive SQL jobs.
Feature Computation: Regularly scheduled jobs compute features that can either be kept private to a project or shared across teams via the Feature Store. These batch jobs are equipped with data quality monitoring tools to detect any anomalies caused by upstream data issues or code changes.
Batch Predictions: For models that do not require real-time predictions, Michelangelo supports batch processing. Offline models can generate predictions on a set schedule or on-demand, with results written back to the data lake for further analysis or use in downstream processes.
Online Pipelines:
Cassandra Integration: For real-time, low-latency predictions, features are precomputed and stored in Cassandra. This is crucial because models deployed in online environments cannot directly access HDFS, and real-time feature computation from Uber’s production databases may not be feasible due to performance constraints.
Real-Time Feature Computation: Michelangelo supports both batch precompute and near-real-time feature computation. Batch precompute involves periodically loading historical features from HDFS into Cassandra. Near-real-time computation leverages Kafka and Samza to process data streams, generating features on-the-fly and storing them in Cassandra for immediate access.
Feature Store
Michelangelo features a centralized Feature Store that acts as a repository for shared features across different teams and projects within Uber. The Feature Store serves two main purposes:
Feature Sharing: Teams can add features to the Feature Store with minimal additional metadata. This enables other teams to discover and reuse these features, significantly reducing redundant work and improving data quality across the organization.
Feature Access: Features stored in the Feature Store can be accessed both online and offline. During model training, features are pulled from the Feature Store using a canonical name, ensuring consistency between training and prediction data. In online prediction scenarios, the same canonical name is used to fetch precomputed feature values from Cassandra.
Domain-Specific Language (DSL) for Feature Transformation
Michelangelo also provides a Domain-Specific Language (DSL), which allows users to select, transform, and manipulate features at both training and prediction times. The DSL, a subset of Scala, includes functions for common data transformations, such as filling missing values, normalizing data, or converting timestamps into more useful representations like hour-of-day or day-of-week. Importantly, the same DSL expressions are used during both training and prediction, ensuring consistency across different stages of the workflow.
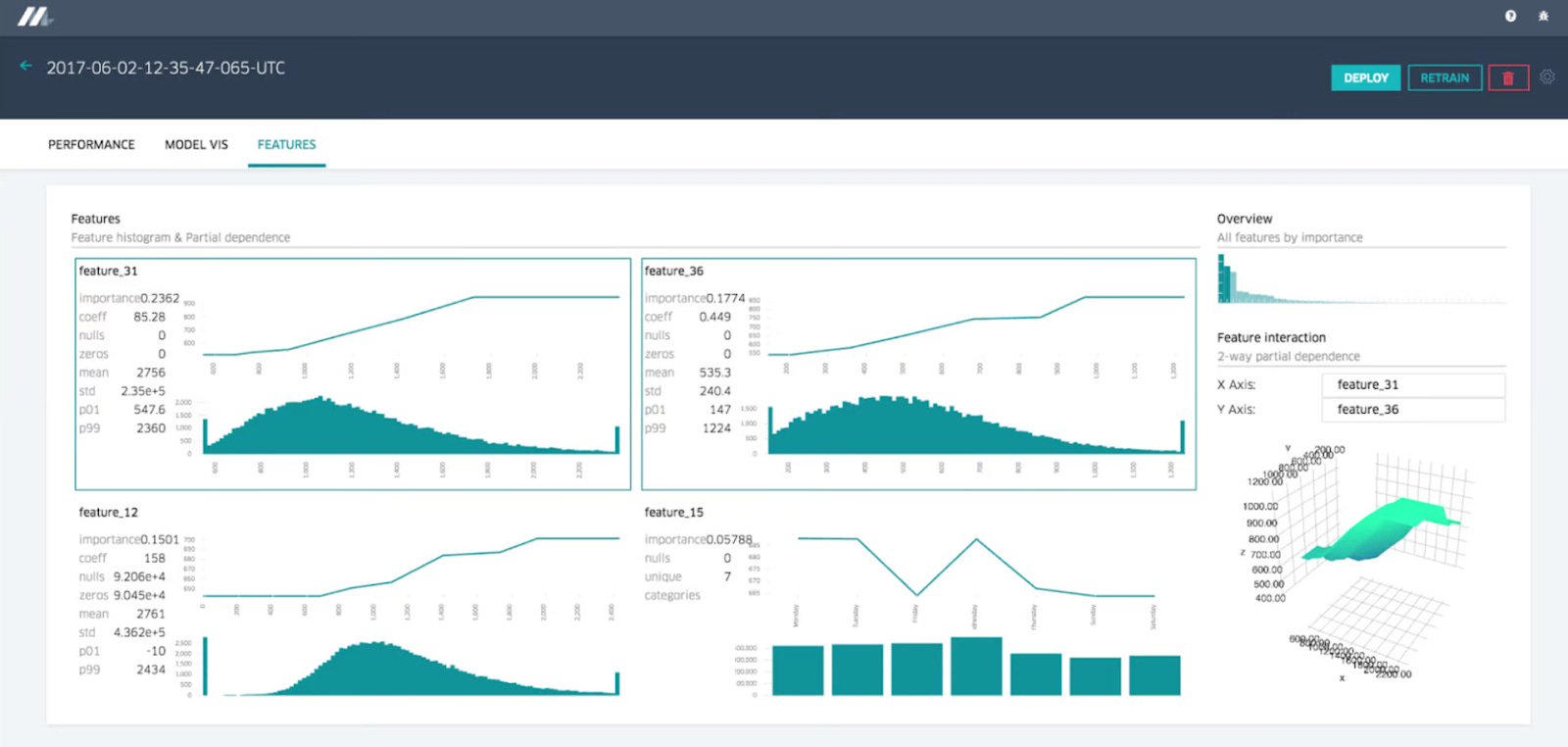
Image credits: https://www.uber.com/en-IN/blog/michelangelo-machine-learning-platform/
2. Model Training
Michelangelo supports a wide range of model types and training algorithms, including decision trees, linear and logistic regression models, unsupervised learning algorithms like k-means clustering, time series models, and deep neural networks. The platform's distributed training system is designed to scale efficiently, handling everything from small, quick iterations to large-scale training on billions of samples.
Model Configuration:
A model configuration in Michelangelo specifies several key elements: the type of model, hyperparameters, data source references, and any feature transformations (expressed via the DSL).
The configuration also includes the compute resources required for training, such as the number of machines, memory allocation, and whether to utilize GPUs for deep learning tasks.
Distributed Training:
Training jobs are distributed across a YARN or Mesos cluster, allowing for parallel processing and efficient resource utilization. This setup is crucial for handling Uber's large-scale data and compute needs.
During training, Michelangelo computes standard performance metrics like ROC curves and PR curves for classification tasks, as well as other relevant metrics for different model types.
Hyperparameter Optimization and Partitioned Models:
Michelangelo offers built-in support for hyperparameter tuning, allowing users to perform grid search or random search to find the optimal model configuration.
Additionally, the platform supports partitioned models, where data is split into partitions (e.g., by geographic region), and separate models are trained for each partition. This is particularly useful for Uber’s global operations, where local models can often outperform a single global model.
Model Repository:
After training, the model’s configuration, learned parameters, and evaluation metrics are stored in Michelangelo’s model repository. This repository, built on Cassandra, allows for easy access, comparison, and analysis of different model versions.
3. Model Evaluation
In the model evaluation phase, Michelangelo provides tools to thoroughly analyze and compare trained models. Given that many models may be trained during the exploration phase, keeping track of their performance and configuration is crucial.
Evaluation Reports:
Each trained model is associated with a comprehensive evaluation report. This report includes a range of metrics and visualizations tailored to the model type, such as ROC and PR curves for classifiers or regression metrics for predictive models.
The evaluation report also contains a detailed breakdown of feature importance, allowing users to understand which features have the most impact on the model's predictions.
Visualization Tools:
For complex models like decision trees, Michelangelo offers sophisticated visualization tools. These tools enable users to drill down into individual trees, examine split points, and assess the importance of features at various nodes. The visualization also supports “what-if” analysis by allowing users to input hypothetical feature values and see how the model's predictions would change.
Feature Reports:
Michelangelo generates feature reports that rank features by their importance to the model. These reports include partial dependence plots that illustrate how changes in a single feature value impact the model's predictions, as well as two-way partial dependence plots that explore feature interactions.
Shameless plug:
Machine Learning Engineering Bootcamp
Learn the intricacies of designing and implementing robust machine learning systems. This course covers essential topics such as ML architecture, data pipeline engineering, model serving, and monitoring. Gain practical skills in deploying scalable ML solutions and optimizing performance, ensuring your models are production-ready and resilient in real-world environments.
4. Model Deployment
Michelangelo supports multiple modes of model deployment, each tailored to different use cases and operational requirements:
Offline Deployment:
In offline deployment, models are deployed to containers that run Spark jobs for batch predictions. These jobs can be triggered on-demand or scheduled at regular intervals, with results stored in the data lake for downstream processing or direct access by users.
Online Deployment:
For real-time applications, models are deployed to an online prediction service cluster, which typically consists of hundreds of machines. This cluster handles network RPC calls from client services, making predictions based on incoming feature data.
Online deployment is particularly crucial for Uber’s operational systems, where low latency and high availability are paramount.
Library Deployment:
Michelangelo also supports library deployment, where models are embedded as a library within another service and invoked via a Java API. This mode is ideal for scenarios where models need to be tightly integrated with existing services.
Model Versioning and A/B Testing:
Michelangelo’s deployment system supports the deployment of multiple model versions simultaneously, allowing for smooth transitions between models and safe A/B testing. Users can deploy a new model under the same tag as an old one, enabling client services to seamlessly switch to the updated model without code changes.
Automation and Continuous Deployment:
Many teams at Uber automate the process of model retraining and deployment using Michelangelo’s API. This is particularly useful for use cases like UberEATS delivery time predictions, where models are regularly updated based on new data.
5. Making Predictions
Once deployed, models in Michelangelo are used to generate predictions based on incoming data. The prediction process is tightly integrated with the feature engineering and data management components of the platform.

Regression model reports show regression-related performance metrics.
Feature Processing:
At prediction time, the raw features are processed using the DSL expressions defined during model configuration. These expressions may include transformations, aggregations, or lookups in the Feature Store, ensuring that the features fed into the model are consistent with those used during training.
Online Predictions:
For online models, predictions are made in real-time as client services send feature vectors to the prediction service cluster. The predictions are then returned over the network, with low latency being a critical requirement.
Offline Predictions:
Offline predictions are typically generated in bulk and stored in the data lake. These predictions can be accessed through SQL-based query tools or used as input for further batch processing.
Model Referencing:
When making predictions, models are identified by a unique UUID or an optional tag. This system allows for flexible model management, including side-by-side comparisons of different models and the ability to deploy and test new models without disrupting existing services.
6. Monitoring and Feedback
After deployment, it is crucial to monitor model performance and ensure that predictions remain accurate and reliable over time. Michelangelo includes built-in tools for monitoring predictions and providing feedback to improve future models.

Binary classification performance reports show classification-related performance metrics.
Prediction Monitoring:
Michelangelo monitors the performance of deployed models by tracking key metrics such as prediction accuracy, latency, and throughput. This monitoring is
Impact on Uber’s Operations
Since its inception, Michelangelo has been a game-changer for Uber. It has enabled the company to scale its machine learning efforts, driving innovations across various domains:
Dynamic Pricing: Michelangelo powers Uber’s dynamic pricing models, which adjust ride prices in real-time based on demand, supply, and external factors like weather conditions.
ETA Prediction: One of the most critical aspects of Uber’s service is providing accurate ETAs. Michelangelo’s models analyze historical trip data, traffic patterns, and driver availability to predict arrival times with high accuracy.
Fraud Detection: Michelangelo’s real-time anomaly detection models help Uber identify and mitigate fraudulent activities, ensuring a safer platform for both riders and drivers.

What's Next: Exploring Michelangelo 2.0
In Part 2 of this blog series, we'll dive into the challenges with Michelangelo 1.0 and the evolution from Michelangelo 1.0 to Michelangelo 2.0 addressing those challenges. We'll explore how Michelangelo 2.0 introduced a more comprehensive framework for ML quality, advanced support for deep learning models, and enhanced collaboration tools. Additionally, we'll look at how the platform integrated and streamlined the diverse ML tooling ecosystem, providing a more cohesive and productive developer experience.
If you liked this newsletter, check out my upcoming courses:
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML and Causal Inference, to drive product growth.
AI/ML Projects for Data Professionals
Gain hands-on experience and build a portfolio of industry AI/ML projects. Scope ML Projects, get stakeholder buy-in, and execute the workflow from data exploration to model deployment. You will learn to use coding best practices to solve end-to-end AI/ML Projects to showcase to the employer or clients.
Machine Learning Engineering Bootcamp
Learn the intricacies of designing and implementing robust machine learning systems. This course covers essential topics such as ML architecture, data pipeline engineering, model serving, and monitoring. Gain practical skills in deploying scalable ML solutions and optimizing performance, ensuring your models are production-ready and resilient in real-world environments.
Not sure which course aligns with your goals? Send me a message on LinkedIn with your background and aspirations, and I'll help you find the best fit for your journey.
 | A guest post by
|