



Advanced Recommender Systems Series – Part 1/3
Discover the limitations of content-based and collaborative filtering, from cold start to scalability. Learn how deep learning and LLMs enhance personalization by capturing complex user preferences.

👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams.
Welcome to the first blog of our Advanced Recommender Systems series, in collaboration with Arun Subramanian!
Building on the foundation laid in the Building Your Own Recommender Systems series, this new series explores cutting-edge approaches that overcome the limitations of traditional methods.
In the previous series, we discussed:
Part 1: Introducing of recommender systems and high-level architecture
Part 2: Evaluating recommender systems, focusing on metrics that assess their effectiveness.
Part 3: Building a content-based recommender system, a foundational approach that uses item attributes to make personalized recommendations.
Part 4: Building a collaborative-filtering based recommender system, an approach that leverages user-item interactions to uncover patterns and preferences.
While these approaches are powerful, they struggle with real-world complexities such as sparse data, cold-start problems, and limited semantic understanding. As user needs become more nuanced, and data continues to grow in scale and diversity, we must turn to advanced methods like deep learning and large language models (LLMs) to push the boundaries of what recommender systems can achieve.
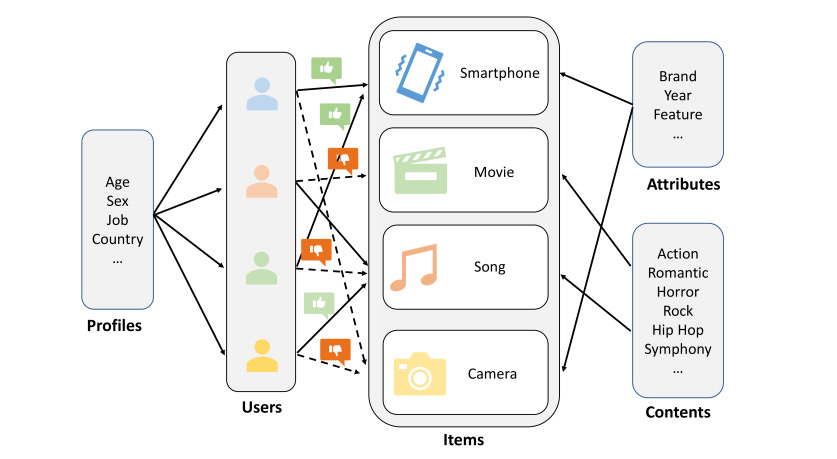
Image Reference: https://arxiv.org/html/2206.02631v2
In this blog, the first of the series, we’ll:
Highlight the key limitations of content-based and collaborative filtering approaches.
Introduce the promise of deep learning and LLM-based techniques in addressing these challenges.
Get ready to explore the future of recommender systems—one blog at a time!
Limitations of Content & Collaborative Filtering
Traditional recommender systems like content-based filtering and collaborative filtering have inherent limitations that become particularly apparent in complex, real-world scenarios:
Semantic Understanding Constraints Traditional methods typically rely on surface-level features or historical interactions, which means they struggle to capture the nuanced, contextual understanding of user preferences. For instance, a content-based system recommending movies might only match genres or surface-level attributes, missing deeper semantic connections.
Example Scenario: Consider a user who enjoys psychological thrillers with complex narrative structures. A traditional content-based system might recommend movies simply because they share the "thriller" genre. However, this approach fails to understand the subtle elements that truly appeal to the user - like narrative complexity, psychological depth, or unique storytelling techniques.

Cold Start and Sparse Data Challenges Collaborative filtering depends heavily on user-item interaction history. In scenarios with limited data - such as new users, new items, or niche content domains - these traditional methods perform poorly.
Practical Illustration: Imagine a streaming platform introducing a new independent film genre. Traditional recommender systems would struggle to recommend these films because:
There's minimal interaction history
The genre lacks established user-item interaction patterns
Surface-level features might not capture the genre's unique appeal

Oversimplified Preference Modeling Traditional matrix factorization and collaborative filtering techniques linearize user preferences, which oversimplifies the intricate, multi-dimensional nature of human tastes.
Real-world Example: A music recommendation system using traditional methods might recommend songs based on genre and previous listening history. However, a user's musical preference could be influenced by:
Mood
Time of day
Cultural background
Emotional resonance
Subtle musical characteristics not captured by basic genre tags
Contextual Limitations Conventional recommender systems often ignore critical contextual information that significantly influences user preferences.
Illustrative Case: A food delivery recommendation system using traditional methods might suggest restaurants based solely on cuisine type and past orders. However, real-world food choices are influenced by:
Time of day
Weather
Current dietary preferences
Social context
Nutritional goals

To address these limitations, we turn to more sophisticated techniques powered by deep learning and large language models (LLMs). These advanced approaches enable us to build more accurate and personalized recommendation systems.
Enter Deep Learning and LLM Approaches
Before diving into these advanced systems, let’s revisit two foundational concepts: vectorization and word embeddings.

Revisiting Vectorization and Word Embeddings
Before diving into deep learning and LLM-based recommenders, let's briefly revisit the concepts of vectorization and word embeddings.
Vectorization is the process of converting textual or categorical data into numerical representations. This is crucial for machine learning algorithms, as they can only process numerical data.
Word embeddings are dense vector representations of words, where similar words have similar vectors. These embeddings capture semantic and syntactic information about words, allowing us to perform tasks like similarity analysis, word analogies, and text classification.
Word2Vec: A Classic Word Embedding Technique
Word2Vec is a popular technique for learning word embeddings. It works by training a neural network on a large corpus of text. The network learns to predict a target word given its context words. In the process, it learns to represent words as dense vectors, where similar words have similar vectors.
Let's take a look at a sample pre-trained model 'glove-twitter-25' from gensim that's 100MB in size. Size is the only reason to choose this model for download, even though it is not technically using Word2Vec embedding technique. If you have the time & network bandwidth, you could try downloading "word2vec-google-news-300" (1700 MB) and play with it in a similar fashion to identify similar words. Both help you quickly understand how word embeddings work. You can find more info regarding the Google Word2Vec and Twitter Glove models from here and here.
Here's a Python code snippet demonstrating how to use a pre-trained word embedding model to find similar words:
with warnings.catch_warnings():
warnings.simplefilter("ignore")
wv = api.load('glove-twitter-25')
wv.most_similar('twitter')
# output
[('facebook', 0.948005199432373),
('tweet', 0.9403423070907593),
('fb', 0.9342358708381653),
('instagram', 0.9104824066162109),
('chat', 0.8964964747428894),
('hashtag', 0.8885937333106995),
('tweets', 0.8878158330917358),
('tl', 0.8778461217880249),
('link', 0.8778210878372192),
('internet', 0.8753897547721863)]
This demonstrates how embeddings capture relationships between words and can be extended to recommendation tasks. If you have more bandwidth, try the larger word2vec-google-news-300 model for even richer embeddings.
Closing Thoughts:
Huge Thanks to Arun Subramanian! for the collaboration and for providing his expertise in this domain. The journey of building recommender systems is as much about understanding user preferences as it is about addressing the technical challenges inherent in traditional methods. Content-based and collaborative filtering techniques laid a strong foundation, offering valuable insights into personalized recommendations.
However, their limitations—such as lack of semantic understanding, challenges with sparse data, oversimplified preference modeling, and inability to incorporate contextual factors—highlight the need for more advanced approaches.
Deep Learning methods represent a significant leap in recommender systems, making it possible to achieve higher levels of personalization and accuracy.
This transition from traditional techniques to cutting-edge approaches underscores the evolving nature of recommender systems, bridging the gap between algorithmic innovation and real-world user satisfaction. Join us as we embark on this exciting journey to explore the next-generation tools and techniques shaping the future of recommendations.
Check out my upcoming courses:
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML and Causal Inference, to drive product growth.
AI/ML Projects for Data Professionals
Gain hands-on experience and build a portfolio of industry AI/ML projects. Scope ML Projects, get stakeholder buy-in, and execute the workflow from data exploration to model deployment. You will learn to use coding best practices to solve end-to-end AI/ML Projects to showcase to the employer or clients.
Machine Learning Engineering Bootcamp
Learn the intricacies of designing and implementing robust machine learning systems. This course covers essential topics such as ML architecture, data pipeline engineering, model serving, and monitoring. Gain practical skills in deploying scalable ML solutions and optimizing performance, ensuring your models are production-ready and resilient in real-world environments.
Not sure which course aligns with your goals? Send me a message on LinkedIn with your background and aspirations, and I'll help you find the best fit for your journey.