



Advanced Recommender Systems Series – Part 2/3
Dive into the second blog of the series, exploring next-gen solutions beyond traditional recommender system.

👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams.
Welcome to the second blog in our Advanced Recommender Systems series, created in collaboration with Arun Subramanian! In this series, we dive deep into next-generation approaches that address the limitations of traditional recommender systems and pave the way for more sophisticated and scalable solutions.
In the first blog, we:
Highlighted the key challenges of content-based and collaborative filtering methods, such as sparse data, cold-start problems, and limited semantic understanding.
Explored the potential of advanced techniques like deep learning and large language models (LLMs) in tackling these issues.
As we move forward, we’re focusing on Neural Network Recommender Systems—a game-changing approach that leverages the power of deep learning to model complex relationships, learn richer user-item representations, and provide highly personalized recommendations at scale.

Image Reference: https://arxiv.org/html/2206.02631v2
In this blog, you’ll learn:
The foundational concepts behind neural network-based recommender systems.
How embeddings, activation functions, and optimization techniques come together to create effective models.
The benefits and challenges of implementing these systems in real-world scenarios.
Join us as we unravel the intricacies of neural networks in recommender systems and set the stage for even more advanced discussions in the series. Let’s continue pushing the boundaries of recommendation technologies—one concept at a time!
Why Neural Networks?
A neural network is a computational model inspired by the human brain, comprising interconnected nodes (neurons) arranged in layers. This structure allows the network to process information hierarchically, making it ideal for capturing complex patterns and relationships in data—an essential requirement for advanced recommender systems.
Using Keras, a powerful deep learning API compatible with JAX, TensorFlow, and PyTorch, we can efficiently design, train, and deploy neural network models. If you're new to Keras, check out its documentation to get started.
Neural Networks Architecture
Below is an overview of the layers typically used in neural network-based recommenders:
Input Layer:
The input layer serves as the entry point for raw data into the neural network. Each neuron in this layer represents a feature or variable from the dataset. For a recommender system, this could include:
User IDs: Representing individual users.
Item IDs: Representing the items being recommended.
Optional Features: User attributes (age, location) or item metadata (genre, price).
This layer does not perform any computation—it simply organizes and feeds the data into the network.
Embedding Layer:
The embedding layer transforms sparse, high-dimensional data into dense, low-dimensional vectors.
What Are Embeddings?
Dense vector representations where similar entities are closer together in a high-dimensional space.How Are Embeddings Learned?
Through training, embeddings are optimized to capture latent relationships between users and items.Why Are Embeddings Important?
They enable generalization and allow recommendations even for unseen user-item pairs.
Hidden Layers:
Hidden layers process embeddings to extract complex patterns.
Nodes in these layers are connected to nodes in the previous and subsequent layers.
The connections between nodes have weights and biases, which are adjusted during training.
Neural networks learn by adjusting the weights and biases of their connections. When trained on a large dataset, the network learns to identify patterns and relationships between data points. In the context of word embeddings, the network learns to represent words as vectors in a high-dimensional space, where similar words are closer together.
Output Layer:
Produces the final output of the network (e.g., predicted rating or item probabilities)
The number of neurons in the output layer depends on the specific task (e.g., classification, regression).
Often uses a softmax activation function for probability distribution, defined as:
where:
x_i is the input to the i-th node in the output layer. exp(x_i) is the exponential of x_i. sum(exp(x_j)) is the sum of the exponentials of all inputs to the output layer. The softmax function ensures that the output values are between 0 and 1 and sum up to 1, making them interpretable as probabilities.
Key Concepts in Training Neural Networks
Forward Propagation
Forward propagation is the process by which input data flows through the network to generate predictions.
Information Flow: Data moves from the input layer, through the hidden layers, and finally to the output layer.
Weighted Calculations: Each layer applies weights, biases, and activation functions to its inputs, passing the transformed outputs to the next layer.
Backpropagation and Gradient Descent
Backpropagation and gradient descent are the core of the training process.
Error Calculation: The difference between predicted and actual values (loss) is computed using a loss function (e.g., mean squared error).
Weight Updates: Gradients of the loss function with respect to model parameters (weights and biases) are calculated. Parameters are updated in the direction that minimizes the loss.
Learning Rate: Determines the step size for updates. Too small a learning rate slows training; too large can cause overshooting.
Regularization and Dropout
Regularization techniques prevent overfitting by discouraging the model from memorizing the training data.
L2 Regularization: Adds a penalty proportional to the square of weights to the loss function.
Dropout: Randomly "drops out" a fraction of neurons during training, forcing the network to learn more robust representations.
Gradient Descent and Optimizers
Gradient descent is an optimization algorithm used to minimize the loss function. A loss function typically measures the discrepancy between the predicted output and the actual target. It could be defined using different metrics such as mean squared error or cross-entropy loss. Gradient Descent involves calculating the gradient of the loss function with respect to the model's parameters and updating the parameters in the direction of the negative gradient. The learning rate determines the step size in the gradient descent update. A smaller learning rate leads to slower convergence but more accurate results, while a larger learning rate can lead to faster convergence but may overshoot the optimal solution.
Stochastic Gradient Descent (SGD): Updates the parameters using the gradient of a single training example.
Adam: A more advanced optimizer that combines the best aspects of SGD and momentum. It adapts the learning rate for each parameter.
Activation Functions Activation functions introduce non-linearity into the network, enabling it to learn complex patterns. Common activation functions include:
ReLU (Rectified Linear Unit): f(x) = max(0, x)
Sigmoid: f(x) = 1 / (1 + exp(-x))
Tanh (Hyperbolic Tangent): f(x) = (exp(x) - exp(-x)) / (exp(x) + exp(-x))
By iteratively adjusting the weights and biases of the neural network, the model learns to effectively represent users and movies in a latent space, enabling accurate predictions and personalized recommendations. By understanding these fundamental concepts, you can build and train neural networks for various tasks, including recommender systems. To gain a deep appreciation, you can head over to
https://playground.tensorflow.org/
and try playing the neural network building exercise to get an intuitive hands-on feel.
Hands-On: Building a Neural Network Recommender
Let’s try this hands-on.

Once the model is setup, we can try to fit the model and get Top N recommendations

Model Insights
Once we are done building the model, let’s randomly pick a user, understand his preferences and predict recommendations for him. For our experiment, I picked an user (userId 289) who rated ‘Star Wars’ higher. Among his/her top rated movie list, we could find both Comedy/Romance (Sound of Music, Casablanca) , Action/Sci-Fi (Star Wars, E.T.) kind of movies. And his average rating for Romance is 3.8 across 24 movies, while average rating for Sci-Fi is 3.5 across 33 movies.
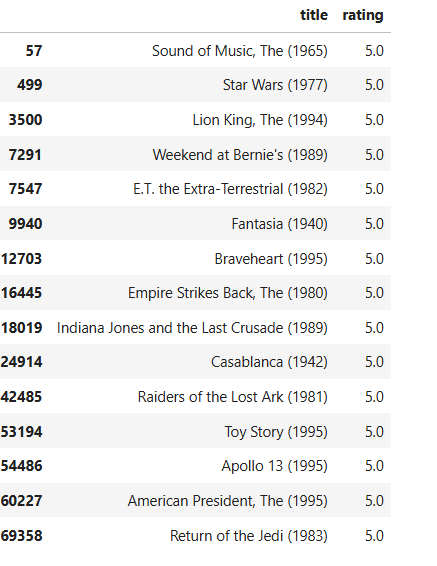
Looking at the recommendations from our neural net model, the results are more biased towards Romance. Our deep learning model could be more influenced by high ratings for the Romance genre. Note that this neural net model is a simple feedforward neural network designed specifically for collaborative filtering and we are not using any of the user/item features.
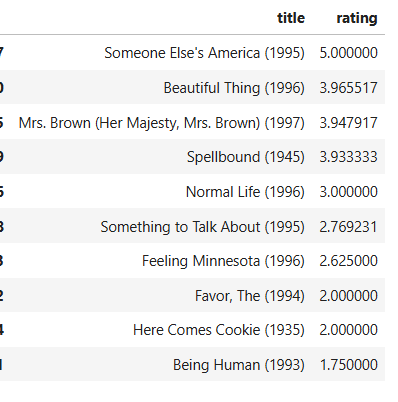
There is still an opportunity to improve the recommendations by embedding additional user/item features and (or) moving towards Recurrent Neural Networks (RNNs) that are better equipped for handling sequential data. In fact, RNNs were a crucial stepping stone in the evolution of Transformer architecture and Large Language models.
For quickly experimenting with various neural net architecture and techniques, testing different activation functions, adding layers and tuning hyperparameters, check out Librecommender. LibRecommender provides an easy-to-use, high-level abstraction for recommender systems focused on the end-to-end recommendation process. It contains a training(libreco) and serving(libserving) module to let users quickly train and deploy different kinds of recommendation models. You can experiment with multiple different algorithms (DeepFM, RNN4Rec, TwoTower, etc.) quickly without a lot of overhead.
And if you are wondering, how Recommendation Systems are built and managed at large scale in companies like Amazon, check out this blog about DSSTNE from AWS. Amazon's Deep Scalable Sparse Tensor Network Engine (DSSTNE) is a high-performance deep learning framework specifically designed for recommendation systems. It excels at handling large-scale sparse datasets, making it ideal for real-world applications.
Closing Thoughts:
Building a neural network-based recommender system is an exciting journey that bridges the gap between raw data and meaningful insights. While our model demonstrates how embeddings and deep learning principles can personalize recommendations, it is only the tip of the iceberg. The field of recommendation systems is vast and continuously evolving, with opportunities to incorporate richer features, experiment with advanced architectures, and optimize for scalability in real-world applications.
In the next section of this series, we’ll take a significant leap forward and explore how Large Language Models (LLMs) are revolutionizing recommendation systems. With their ability to process and contextualize vast amounts of unstructured data, LLMs are pushing the boundaries of personalized experiences, offering new possibilities for understanding user intent and delivering nuanced recommendations.
Stay tuned as we delve deeper into the world of LLM-powered recommendation systems!
Check out my upcoming courses:
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML and Causal Inference, to drive product growth.
AI/ML Projects for Data Professionals
Gain hands-on experience and build a portfolio of industry AI/ML projects. Scope ML Projects, get stakeholder buy-in, and execute the workflow from data exploration to model deployment. You will learn to use coding best practices to solve end-to-end AI/ML Projects to showcase to the employer or clients.
Machine Learning Engineering Bootcamp
Learn the intricacies of designing and implementing robust machine learning systems. This course covers essential topics such as ML architecture, data pipeline engineering, model serving, and monitoring. Gain practical skills in deploying scalable ML solutions and optimizing performance, ensuring your models are production-ready and resilient in real-world environments.
Not sure which course aligns with your goals? Send me a message on LinkedIn with your background and aspirations, and I'll help you find the best fit for your journey.