

Applying the A/B Testing Framework to an Industry Example
Two candidates. Same A/B test. Completely different outcomes. Learn how the Objective → Metrics → Design → Decision framework separates test runners from product thinkers.


This is Part 2 of our A/B Testing Interview series. If you haven’t read Part 1 yet, I recommend starting there to learn the Objective → Metrics → Design → Decision framework that we’ll be applying in this post.
[← Back to Part 1: Learn the Framework]
In Part 1, I introduced a four-step framework for answering any A/B testing interview question: Objective → Metrics → Design → Decision. Now let’s see this framework in action with a realistic interview scenario.
👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams.
The Interview Question
“Our mobile app has a ‘Save for Later’ button at the bottom of product pages. Should we A/B test moving it to the top?”
I choose this example because it’s representative of real product decisions. It’s not obviously right or wrong, it requires business judgment, and there are multiple valid approaches depending on your objectives.
Let’s see how two candidates handle this question.
Candidate A:
“Yes, we should test this. I’d set up a 50/50 A/B test where half the users see the button at the top and half see it at the bottom. We’d track the click-through rate on the Save button as our primary metric. Based on a typical conversion rate, we’d probably need around 10,000 users per variant to detect a meaningful difference. We’d run it for two weeks to account for weekly patterns, and if we see a statistically significant increase in saves with p-value less than 0.05, we’d ship the change.”
What Candidate A got right: They clearly know A/B testing mechanics. They mentioned sample size, statistical significance, controlling for weekly patterns, and a primary metric. These are all important technical elements.
What Candidate A missed: Notice what’s completely absent from this answer:
Why are we doing this test?
What business problem are we solving?
What if the button gets more clicks but hurts the overall business?
What will we do if the test fails?
Are there different user segments we should consider?
The interviewer is left wondering if this candidate can think strategically or just execute instructions. They sound like someone who can run a test, but not someone who can decide which tests are worth running.
Shameless Plugs:
A/B Testing Course for Data Scientists and Product Managers
Learn how top product data scientists frame hypotheses, pick the right metrics, and turn A/B test results into product decisions. This course combines product thinking, experimentation design, and storytelling—skills that set apart analysts who influence roadmaps.
Advanced A/B Testing for Data Scientists
Master the experimentation frameworks used by leading tech teams. Learn to design powerful tests, analyze results with statistical rigor, and translate insights into product growth. A hands-on program for data scientists ready to influence strategy through experimentation.
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML, and Causal Inference, to drive product growth.
Candidate B:
Objective: “Before designing this test, I need to understand what we’re trying to achieve. I’m assuming the goal is to increase usage of the Save for Later feature, which presumably drives return visits and ultimately conversions. But I’d want to confirm—are we trying to increase saved items, improve conversion rates for saved items, or reduce cart abandonment? Also, why do we believe moving it to the top would help? Have we seen data showing users miss the button currently, or heard feedback that it’s hard to find?”
Metrics: “Assuming our objective is to increase feature usage and downstream conversion, here’s how I’d measure success. My primary metric would be save rate—the percentage of product page views that result in a save action. This directly measures whether the change achieves our goal.
For secondary metrics, I’d track return visit rate for users who save items, conversion rate on saved items, and time between saving and purchasing. These help us understand not just if behavior changed, but whether it’s valuable.
For guardrail metrics, I’d monitor overall conversion rate from product pages to ensure we’re not accidentally reducing immediate purchases. I’d also track app performance metrics to catch any technical issues.”
Design: “I’d recommend a 50/50 A/B test at the user level, so individuals get a consistent experience across sessions. For sample size, if our current save rate is 5% and we want to detect a 20% relative lift with 80% power, we’d need approximately 15,000 product page views per variant.
I’d run this for at least two weeks regardless of when we hit our sample size, to capture different shopping behaviors and weekly cycles. One concern I have is that power users might behave very differently from casual users. I’d like to ensure we can analyze both segments separately.”
Decision: “I’d ship the change if we see at least a 15% relative lift in save rate with statistical significance and no degradation in our guardrail metrics. The 15% threshold reflects that this is a relatively low-cost change—even a modest improvement is worth implementing.
I’d also segment the analysis by user engagement level. If the button placement helps casual users discover the feature but doesn’t affect power users who already know where it is, that’s still valuable. And if the test fails, I’d want to understand why. Is button placement really the issue, or is there a deeper problem with how users understand the Save for Later feature? That would inform our next iteration.”
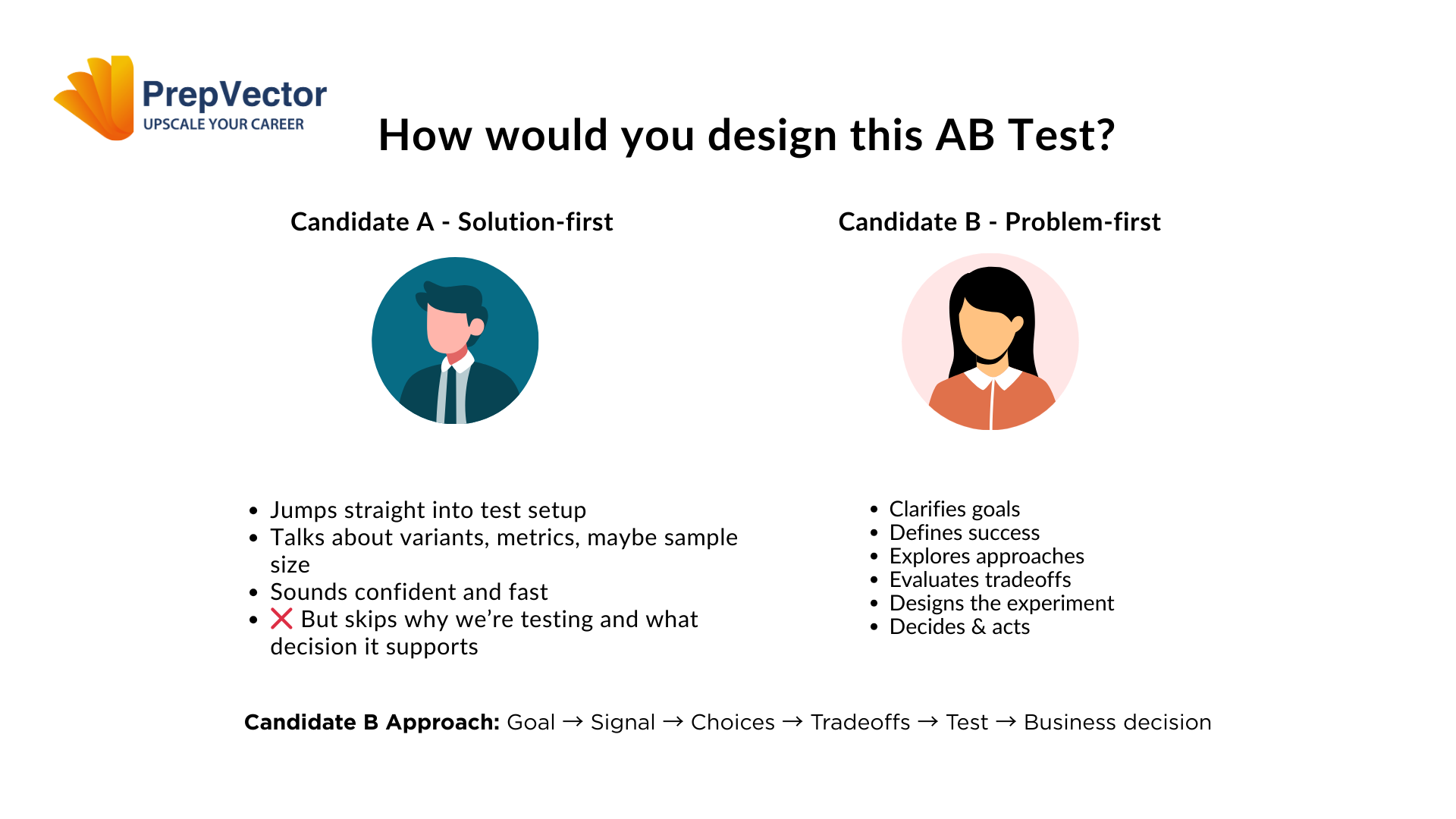
Why Candidate B’s Approach Works
Candidate B covered all the same technical ground as Candidate A, but did three crucial things differently:
First, they established context before diving into details. By starting with objectives, they demonstrated they understand that experiments serve business goals, not the other way around. This is what separates order-takers from strategic thinkers.
Second, they showed awareness of complexity. They didn’t just name metrics—they explained why each metric matters and how they work together. They didn’t just calculate sample size—they explained the tradeoffs and potential confounds. This shows they’ve actually run experiments before and dealt with messy reality.
Third, they connected the experiment to action. They didn’t just say “we’ll look at statistical significance.” They specified what results would lead to what decisions, including what they’d do if the test fails. This proves they understand that the point of testing isn’t to generate p-values—it’s to make better product decisions.
The interviewer listening to Candidate B is thinking: “This person can lead our experimentation program. They won’t just run tests I ask for—they’ll help me figure out which tests we should run in the first place.”
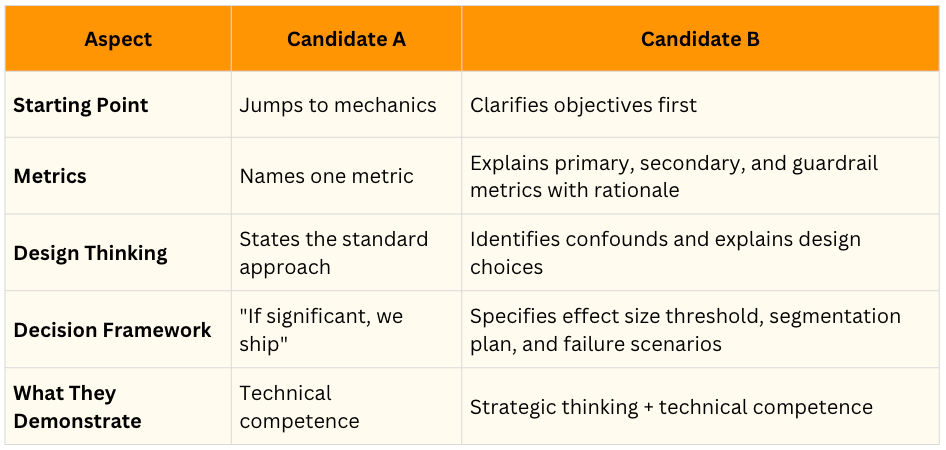
The Key Differences Summarized
Additional Scenarios to Practice
Try applying the framework to these questions:
Scenario 1: “Should we A/B test removing the phone number field from our signup form?”
Scenario 2: “We’re considering testing an AI recommendation algorithm against our current rule-based system. How would you approach this?”
Scenario 3: “Should we test whether showing restaurant ratings as numbers (4.5) performs better than stars (★★★★½)?”
For each scenario, work through: Objective → Metrics → Design → Decision. Write out complete responses as if you’re speaking to an interviewer.
Bringing It All Together
Interviewers are trying to assess whether you can think clearly about experiments in ambiguous situations. The candidates who excel aren’t necessarily those with the most advanced statistical knowledge. They’re the ones who can structure problems, ask clarifying questions, and connect experimental design to business outcomes.
If you’d like to dive deeper into experimentation, here are a few of our learning programs you might enjoy:
A/B Testing Course for Data Scientists and Product Managers
Learn how top product data scientists frame hypotheses, pick the right metrics, and turn A/B test results into product decisions. This course combines product thinking, experimentation design, and storytelling—skills that set apart analysts who influence roadmaps.
Advanced A/B Testing for Data Scientists
Master the experimentation frameworks used by leading tech teams. Learn to design powerful tests, analyze results with statistical rigor, and translate insights into product growth. A hands-on program for data scientists ready to influence strategy through experimentation.
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML, and Causal Inference, to drive product growth.
Not sure which course aligns with your goals? Send me a message on LinkedIn with your background and aspirations, and I’ll help you find the best fit for your journey.
 | A guest post by
|
Great breakdown of strategic vs tactical thinking. The guardrail metrics piece is underrated becuase most people focus only on primary metrics and miss unintended consequences. I've seen teams ship "winning" tests that tanked revenue downstream. The segmentation callout for power users vs casual is also key, especailly when button placement matters more for discovery than convenience.