

Deploying a Two-Tier RAG Chatbot with FastAPI and Streamlit
Deploy the RAG chatbot designed to answer questions from the “Attention is All You Need” research paper, using FastAPI and Streamlit.


In the previous blog, we built a RAG chatbot capable of answering questions about the Attention Is All You Need paper. To make this chatbot accessible, we now deploy it using a two-tier architecture with FastAPI as the backend and Streamlit as the frontend.
👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams.
About the Authors:
Arun Subramanian: Arun is an Associate Principal of Analytics & Insights at Amazon Ads, where he leads development and deployment of innovative insights to optimize advertising performance at scale. He has over 12 years of experience and is skilled in crafting strategic analytics roadmap, nurturing talent, collaborating with cross-functional teams, and communicating complex insights to diverse stakeholders.
Manisha Arora: Manisha is a Data Science Lead at Google Ads, where she leads the Measurement & Incrementality vertical across Search, YouTube, and Shopping. She has 11+ years experience in enabling data-driven decision making for product growth.
Why Two-Tier architecture?
Using a two-tier architecture with Streamlit for the frontend and FastAPI for the backend offers several advantages.
Separation of Concerns
This architecture promotes a clean separation between the user interface and application logic/data processing. Changes to the frontend are less likely to affect the backend. Likewise, you can make significant changes to your application logic, data handling or technology in the backend without causing any disruption on the user experience. You can potentially use the FastAPI backend to connect to multiple frontend applications that need the same business application logic.
Performance and Scalability
Streamlit is designed for rapid development of interactive user experience, while FastAPI is optimized for building high performance APIs. This allows each component to excel at its specific task. You can independently scale frontend and backend depending on the resource requirements for each.
Enhanced Security
You can expose only the frontend to internet traffic while protecting the application logic/data processing in the backend from direct external access. This isolation allows you to implement stricter security measures on the backend such as authentication, protection against injection attacks or handling sensitive data.
Setting up the FastAPI backend
FastAPI is a modern, fast (high-performance), web framework for building APIs with Python based on standard Python type hints. It is designed to be easy to use, efficient, and reliable, making it a popular choice for developing RESTful APIs and web applications. FastAPI has gained popularity due to its simplicity, automatic documentation generation, and excellent performance.
What are APIs?
API stands for Application Programming Interface. Imagine you are in a restaurant and you want to know what food items the restaurant serves. Usually, the server hands you a menu with a list of items available. That menu is analogous to an API for a server.
But an API is more than just a menu. It's also the way you interact with the restaurant.
The menu tells you what you can order (GET, POST, etc.).
Your order is like a Request to the API.
The server taking your order is like the API Endpoint that receives your request.
You specify how you want your food prepared (e.g., "no salt," "well-done"). These are like parameters (eg., request body, request header) you send to the API.
The kitchen is the application (backend) that processes your request.
The server bringing your food is like the response from the API.
The food itself is the data you requested.
What are REST APIs?
Representational State Transfer (REST) APIs are an architectural style for building networked applications, using standard HTTP methods to manage resources, and components like URLs, headers, and body for requests and responses. In a REST API, the server doesn’t store any session state data and hence each request from a client to the server must contain all of the information needed to understand and process the request. They enable communication between different software systems over the internet by adhering to principles like statelessness and a uniform interface.
Setting up Rest API using FastAPI Framework
Below is an example of how to set up a REST API using the FastAPI web framework.
# Setup Data Validation using Pydantic
class InvokeRequest(BaseModel):
input: str # The input field, as expected by your LangChain chain
# Create the FastAPI app
app = FastAPI(title="Langchain Server",
version="1.0",
description="A simple API server using Langchain runnable interfaces")
# add_routes(app, rag_chain)
@app.post("/invoke")
async def invoke(request: InvokeRequest):
try:
data = request.model_dump()
# print(f"Received data: {data}") #Debug
result = rag_chain.invoke(data)
# print(f"Langchain result: {result}") #Debug
answer = result['answer']
sources = [doc.page_content for doc in result['context']] #extract page contents from documents
return JSONResponse(content={"answer": answer, "sources": sources})
except Exception as e:
print(f"Error in /invoke: {e}") #Debug
raise HTTPException(status_code=500, detail=str(e)) # Raise an HTTP exception.
@app.get("/", response_class=HTMLResponse)
async def welcome():
with open("index.html", "r") as f:
html_content = f.read()
return html_content
if __name__=="__main__": import uvicorn uvicorn.run(app,host="127.0.0.1",port=8000)Shameless plugs:
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML, and Causal Inference, to drive product growth.
AI/ML Projects for Data Professionals
Gain hands-on experience and build a portfolio of industry AI/ML projects. Scope ML Projects, get stakeholder buy-in, and execute the workflow from data exploration to model deployment. You will learn to use coding best practices to solve end-to-end AI and ML Projects to showcase to the employer or clients.
Testing the backend using Swagger UI
Swagger UI allows anyone — be it your development team or your end consumers — to visualize and interact with the API’s resources without having any of the implementation logic in place. It’s automatically generated from your OpenAPI (formerly known as Swagger) Specification, with the visual documentation making it easy for back end implementation and client side consumption.
To test your API backend after you launch your server, click on the link
https://127.0.0.1:8000
. This is the “localhost” IP address in Windows 10 and in most OS.This should launch the API locally in your browser. Then navigate to “/docs” from the index page to get to Swagger UI.
In our case, we have two endpoints
/ (GET method):
This endpoint is defined using @app.get(“/”, response_class = HTLMLResponse). It accepts GET requests and reads the content of a HTML file named “index.html” and returns it as an HTML response.
/invoke (POST method):
This endpoint is defined using @app.post(“/invoke”). It accepts POST requests and is designed to take an InvokeRequest(), process it using rag_chain.invoke() and return a JSON response containing the answer and sources.
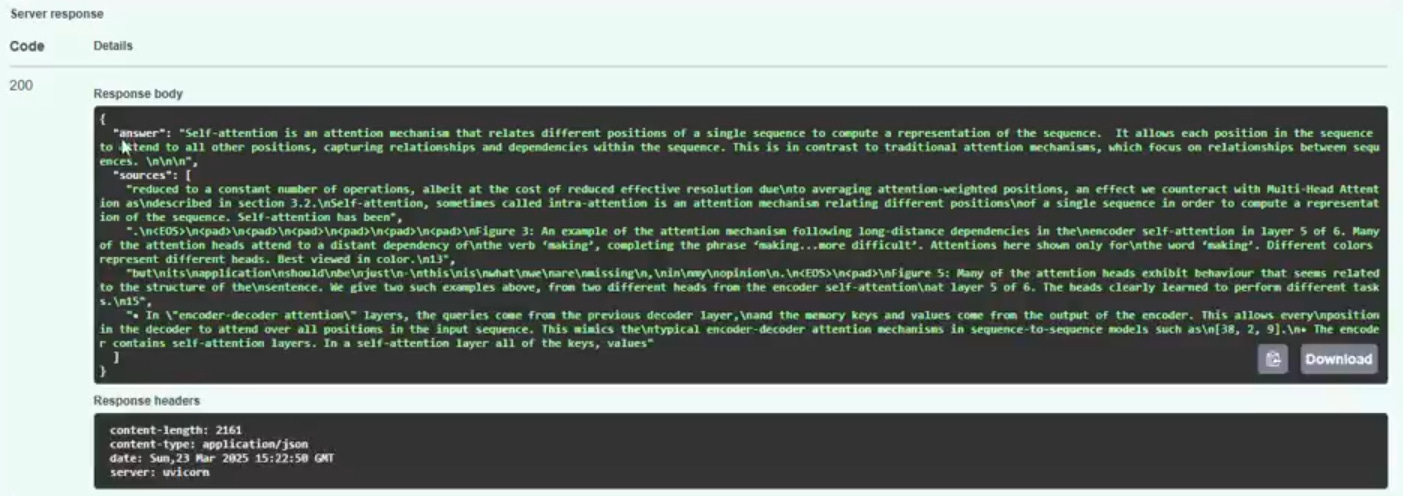
Below is a screenshot of the Swagger UI with both endpoints. You can expand the /invoke endpoint and click on “Try it out”. Then update the request body from default {“input”: “string”} to {“input” : “What is self attention?”} or any other question and click on “Execute”. Now, if you go and check the Response Body, you will see the answer and sources in JSON format. This validates that your API is working fine.
Setting up the Streamlit Frontend
Now that you have successfully launched your API with the application / business logic, setting up a frontend to call that API and get response is simpler. Streamlit is an open-source Python framework for data scientists and AI/ML engineers to deliver dynamic data apps with only a few lines of code. To set up Streamlit frontend, you just need to follow the below code.
def get_groq_response(input_text):
json_body={"input": input_text}
# Add Content-Type header
headers = {'Content-Type': 'application/json'}
response=requests.post("http://127.0.0.1:8000/invoke",
json=json_body, headers=headers)
return response.json()
## Streamlit app
st.title("Attention mechanism QA Chatbot")
st.write("This chatbot uses the LangChain RAG model to answer questions related to attention mechanism in transformer architecture")
input_text=st.text_input("Please enter your question below and the chatbot will provide an answer")
if input_text:
with st.spinner("Generating answer..."):
answer_data = get_groq_response(input_text)
st.subheader("Answer:")
st.write(answer_data["answer"])
st.subheader("Sources:")
st.write("Chatbot used the below page content as context from retriever to answer your question:")
if "sources" in answer_data and answer_data["sources"]:
for source in answer_data["sources"]:
st.write(source)
else:
st.write("No sources found")Playtime Now!
Now that you have all the set pieces in place, it is time to launch your Streamlit dashboard and start playing. After ensuring that your API is still active, launch the frontend using `streamlit run client.py`. You can then start shooting your questions to learn more about the Attention mechanism to the chatbot.
I tried out the following questions
What is the attention mechanism?
What is self-attention?
What is the matrix calculation of self-attention?
What are the components of transformer architecture?
What is the purpose of residual connections?
What are the encoders and decoders?
What are the queries, keys and values used for?

Conclusion
Whoa, you made it to the end!
If you're still with me, you've earned some serious GenAI credentials! My aim was to pack this article with value, and I hope it delivered. We journeyed beyond basic LangChain, wrestling with document loaders, text wrangling, embeddings, and a two-tier Streamlit/FastAPI build – all to forge a real-world RAG Q&A chatbot. This isn't just theory; it's your launchpad from PoC to production-ready applications. Hungry for more GenAI insights? Then stick around – the adventure's just beginning.
Want to take it further? Try integrating different embedding models, optimizing retrieval strategies, or enhancing the frontend UI for a more intuitive user experience!
References
https://python.langchain.com/v0.1/docs/get_started/introduction
Check out my Upcoming Courses:
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML, and Causal Inference, to drive product growth.
AI/ML Projects for Data Professionals
Gain hands-on experience and build a portfolio of industry AI/ML projects. Scope ML Projects, get stakeholder buy-in, and execute the workflow from data exploration to model deployment. You will learn to use coding best practices to solve end-to-end AI/ML Projects to showcase to the employer or clients.
Not sure which course aligns with your goals? Send me a message on LinkedIn with your background and aspirations, and I'll help you find the best fit for your journey.
 | A guest post by
|