

Advanced Recommender Systems Series – Part 3/3
Explore how LLMs revolutionize recommendation systems and learn to build a movie recommender using Ollama, Mistral, and FAISS

👋 Hey! This is Manisha Arora from PrepVector. Welcome to the Tech Growth Series, a newsletter that aims to bridge the gap between academic knowledge and practical aspects of data science. My goal is to simplify complicated data concepts, share my perspectives on the latest trends, and share my learnings from building and leading data teams.
Welcome to the second blog in our Advanced Recommender Systems series, created in collaboration with Arun Subramanian!
In the first two blogs, we:
Part 1 - Highlighted the key challenges of content-based and collaborative filtering methods, such as sparse data, cold-start problems, and limited semantic understanding.
Part 2 - Foundational concepts in Neural Networks like activation functions, embeddings, and optimization methods, and how they power recommender systems
If you’d like to get started with recommender systems, refer to the Building the Recommender Systems series.
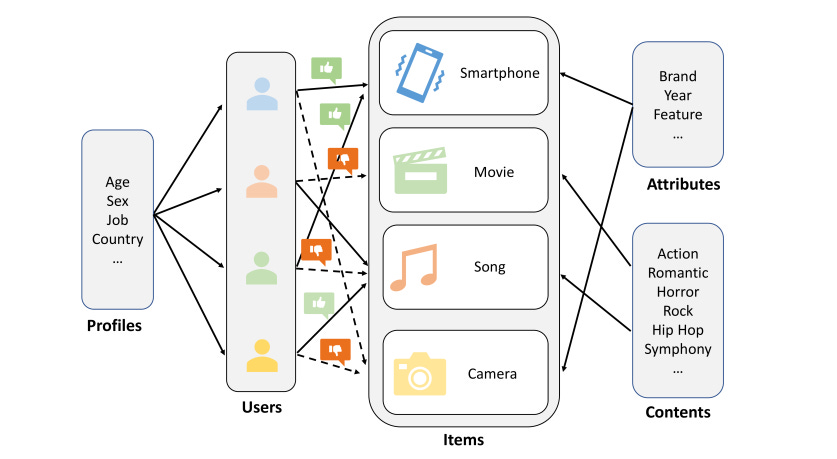
Image Reference: https://arxiv.org/html/2206.02631v2
In this third blog, we’ll shift gears to explore how Large Language Models (LLMs) are revolutionizing recommendation systems. These advanced AI systems can process and generate human-like text, making them ideal for addressing challenges like data sparsity and cold-start problems.
We’ll also take a hands-on approach, demonstrating how tools like Ollama, Mistral, and FAISS can be used to build a movie recommendation system that leverages LLM-generated embeddings. By the end of this blog, you’ll see how LLMs enable sophisticated, personalized recommendations while opening up possibilities for novel use cases.
Join us as we unravel the intricacies of neural networks in recommender systems and set the stage for even more advanced discussions in the series. Let’s continue pushing the boundaries of recommendation technologies—one concept at a time!
From RNNs to Transformers: The Journey to LLMs
RNNs were the early pioneers in processing sequential data. They could capture dependencies in text, making them suitable for tasks like language modeling and machine translation. However, they struggled with the vanishing gradient problem, limiting their ability to learn long-range dependencies.
Advancements with LSTMs and GRUs: To address these limitations, architectures like Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) were introduced. By incorporating memory cells and gates, these models better managed information flow, allowing them to capture longer-term dependencies.
The Rise of Transformers: The advent of the Transformer architecture marked a turning point in natural language processing. By leveraging self-attention mechanisms, Transformers efficiently captured long-range dependencies and allowed for parallel processing, making them faster and more effective than RNNs.
The Era of LLMs: Combining large datasets, powerful hardware, and the Transformer architecture, Large Language Models (LLMs) like GPT-3 and BERT emerged. These models are trained on massive amounts of text, enabling them to generate human-quality text and provide nuanced understanding across tasks. For recommendations, LLMs can extract insights from textual data, generate embeddings, and address challenges like cold-start problems and data sparsity.
How LLMs Power Recommender Systems
LLMs bring unique capabilities to the domain of recommendation systems. Here's how they work:
Textual Data Analysis: With datasets containing textual data (e.g., movie descriptions, user reviews), LLMs extract meaningful embeddings, capturing semantic relationships.
Efficient Search with Vector Databases: Libraries like FAISS (Facebook AI Similarity Search) store and retrieve embeddings efficiently, allowing for rapid similarity searches.
Personalized Recommendations: By comparing embeddings using metrics like cosine similarity, LLMs generate highly personalized and contextually relevant recommendations.

Image Reference: https://blog.vllm.ai/2023/06/20/vllm.html
Building a Movie Recommender with LLMs
Let's build a movie recommender system using the Ollama library to run Mistral LLM locally and generate embedding. We will also utilize FAISS (Facebook AI Similarity Search) library to efficiently do similarity search in vector space. For our experiment, I downloaded a Netflix dataset from Kaggle and filtered it for 'Children & Family Movies, Comedies' genre. Each movie's textual metadata includes the title, genre, plot summary, and cast. This gives us 200 unique rows of movie data to generate embeddings using Mistral LLM, index and search for similar items using FAISS.
Note - With 16GB RAM, it took me close to an hour for the below code to create embeddings and save it even for this small dataset. If you don’t want to wait for an hour, skip that embedding generation step and instead utilize the ‘index’ file saved in GitHub.
Step 1: Understanding the Components
Ollama:
A versatile framework for running large language models (LLMs) locally.
Simplifies the process of deploying and utilizing LLMs.
Provides a user-friendly interface to interact with these models.
Mistral:
A powerful LLM capable of understanding and generating human language.
In this context, it's used to transform textual movie descriptions into numerical representations or embeddings.
These embeddings capture the semantic meaning of the text.
FAISS (Facebook AI Similarity Search):
A library designed to efficiently search for similar vectors in large datasets.
It's ideal for finding movies with similar embeddings, enabling personalized recommendations.
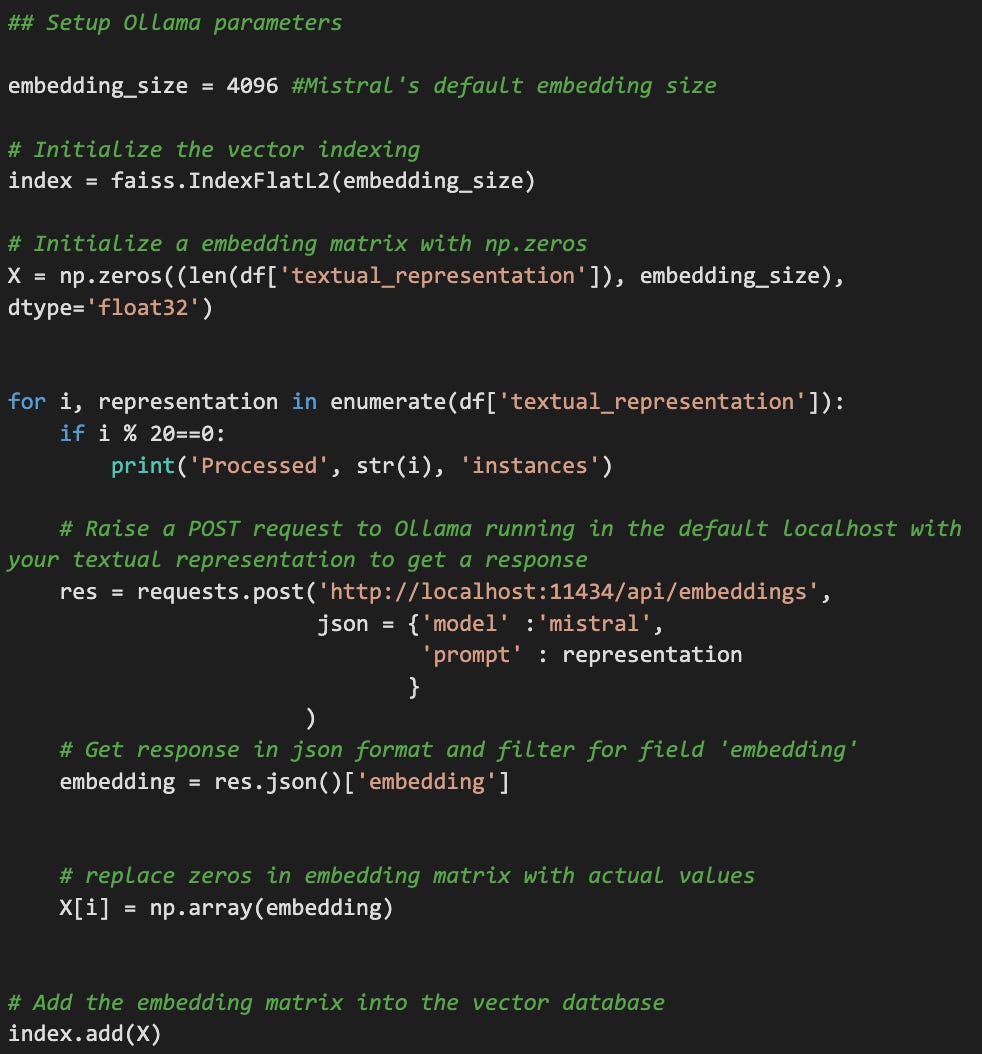
Step 2: Generating and Storing Embeddings
Using the Mistral LLM, we transform each movie's textual metadata into dense vector representations (embeddings). These embeddings are stored in a FAISS vector database for efficient search.
Textual Representation to Embeddings:
Input: A textual description of a movie, including its title, genre, plot summary, cast, and other relevant details.
Ollama and Mistral: The textual description is fed into the Mistral LLM, which processes it and generates a dense vector representation, or embedding.
Embedding: This embedding captures the semantic and syntactic nuances of the movie's description.
Storing Embeddings in FAISS:
Vector Database: The generated embeddings are stored in a FAISS vector database.
Efficient Search: FAISS is optimized for efficient similarity search, allowing for rapid retrieval of movies with similar embeddings.
Finding Similar Movies:
Query Embedding: A new movie description is processed by the Mistral LLM to generate a query embedding.
Similarity Search: The query embedding is compared to the embeddings stored in the FAISS database using similarity metrics like cosine similarity.
Recommendation: The movies with the most similar embeddings are retrieved and recommended to the user.
Benefits of this Approach:
Semantic Understanding: The LLM-powered embedding process allows for a deep understanding of the textual content, leading to more accurate recommendations.
Efficient Search: FAISS ensures rapid retrieval of similar movies, even from large datasets.
Personalized Recommendations: By considering the specific preferences of a user, the system can tailor recommendations to their individual tastes.
Flexibility: The system can be adapted to various recommendation tasks, such as recommending books, articles, or products.
Pre-requisites:
Download and install Ollama
Open Command Prompt -> Ollama run mistral -> Once it is loaded and ready for your prompts, press Ctrl+D -> Run `Ollama ps' to see if the model is loaded and running. We need the server/model to be running in localhost 127.0.0.1:11434. By default, Ollama server runs in the port 11434 unless you bind it to some other port.
The code snippet below helps to generate embeddings and index them using FAISS.
Once the embeddings are indexed and ready for search, we then utilize FAISS index.search() function to get top 10 movies similar to ‘Spy Kids’. If we look at the results generated, we notice that the results are pretty close. Infact, LLMs recommended Spy Kids2 and subsequent sequels as one of the top recommendations. The picture below shows the top 3 recommendations.

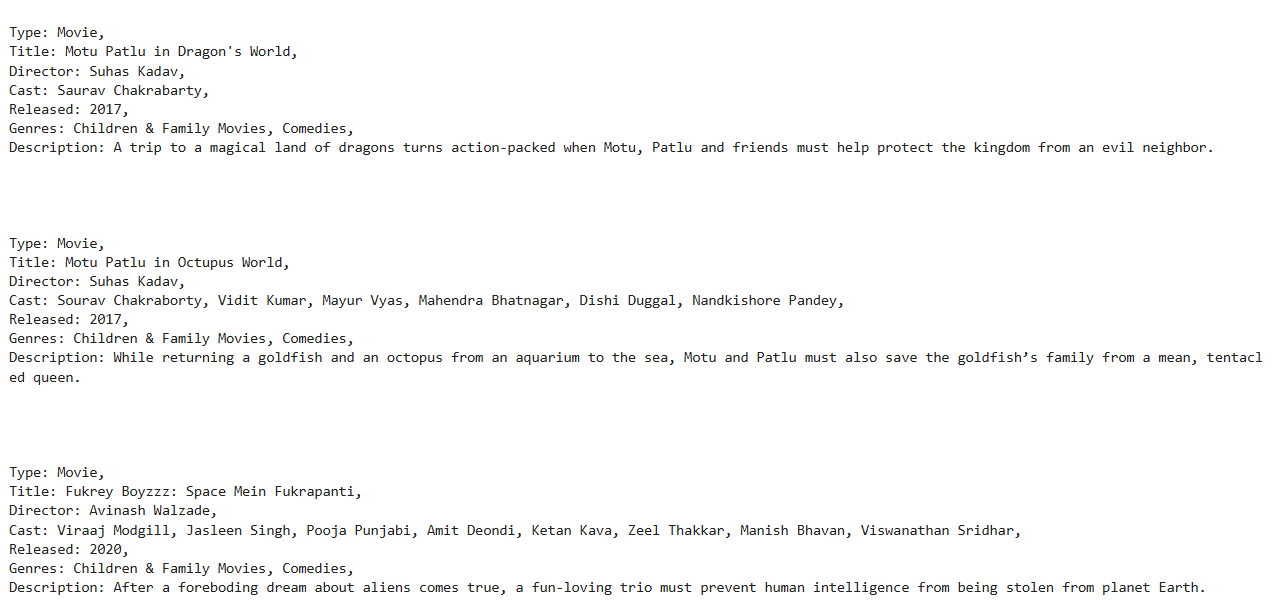
Now, here is an example to witness the true power of LLMs that helps to alleviate data sparsity. This approach can provide recommendations even for an imaginary plot. This is particularly useful for solving cold start problems. I tried passing an imaginary movie data with the title ‘The kid who trained the dragon’ with the description ‘A dragon and a little kid become best friends and fight together to stop a villain’ . LLM clearly understands the context of two entities (kid + dragon, kid + animal, two kids, or two people) joining forces to fight off a villain and makes recommendations that are closer to this imaginary example. The picture below shows top 3 recommendations.
Closing Thoughts:
By leveraging deep learning and large language models (LLMs), we can build more sophisticated and personalized recommender systems. These advanced techniques offer several advantages over traditional methods:
1. Addressing Data Sparsity:
Implicit Feedback: Deep learning models can effectively capture implicit feedback, such as click-through data and purchase history, to infer user preferences even when explicit ratings are scarce.
Contextual Understanding: LLMs can analyze textual data, such as product descriptions and user reviews, to understand the context of user interactions and provide more relevant recommendations.
2. Mitigating the Cold Start Problem:
Transfer Learning: Pre-trained LLMs can be fine-tuned on specific recommendation datasets, allowing for faster and more accurate recommendations, even for new users or items.
Knowledge Graph Embeddings: By incorporating knowledge graphs, we can leverage external knowledge to improve recommendations for cold-start items or users.
3. Improved Recommendation Accuracy and Personalization:
Complex Relationships: Deep learning models can capture complex relationships between users, items, and contextual factors. User-Specific Preferences: LLMs can analyze user behavior and preferences to provide highly personalized recommendations.
By combining the power of deep learning and LLMs, we can create recommender systems that are more accurate, efficient, and capable of adapting to evolving user preferences and item catalogs. Now that you have understood how LLMs work by converting textual representations to vectors and then using that internally to provide responses to our prompts, you should have a good intuition of why LLMs struggle to answer “How many Rs are in the word Strawberry?”. Comment your answers below.
Check out my upcoming courses:
Master Product Sense and AB Testing, and learn to use statistical methods to drive product growth. I focus on inculcating a problem-solving mindset, and application of data-driven strategies, including A/B Testing, ML and Causal Inference, to drive product growth.
AI/ML Projects for Data Professionals
Gain hands-on experience and build a portfolio of industry AI/ML projects. Scope ML Projects, get stakeholder buy-in, and execute the workflow from data exploration to model deployment. You will learn to use coding best practices to solve end-to-end AI/ML Projects to showcase to the employer or clients.
Machine Learning Engineering Bootcamp
Learn the intricacies of designing and implementing robust machine learning systems. This course covers essential topics such as ML architecture, data pipeline engineering, model serving, and monitoring. Gain practical skills in deploying scalable ML solutions and optimizing performance, ensuring your models are production-ready and resilient in real-world environments.
Not sure which course aligns with your goals? Send me a message on LinkedIn with your background and aspirations, and I'll help you find the best fit for your journey.